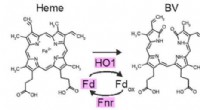
1. Pré-processamento de dados - Entrada:dados de RNA-seq de célula única (matriz de contagem)
- Controle de qualidade (QC):Remova células e genes de baixa qualidade
- Normalização de dados:normalize os dados para corrigir preconceitos técnicos
2. Agrupamento - Execute clustering nos dados normalizados para identificar clusters de células
- Diferentes métodos de agrupamento podem ser usados (por exemplo, k-means, agrupamento hierárquico, Louvain)
3. Identificação do gene marcador - Para cada cluster:
- Calcule a expressão média de cada gene nas células do cluster
- Compare a expressão média dos genes no cluster com a de outros clusters
- Identificar genes que são altamente expressos no cluster em comparação com outros clusters
4. Validação do gene marcador - Critérios adicionais podem ser aplicados para selecionar genes marcadores:
- Mudança de dobra:Considere genes com uma mudança de dobra alta entre o cluster e outros clusters
- Significância estatística:Use testes estatísticos (por exemplo, teste t, teste de Wilcoxon) para avaliar a significância das diferenças de expressão
- Especificidade:Garantir que os genes marcadores sejam expressos seletivamente no cluster de interesse
5. Interpretação e Visualização - Analisar as funções e vias associadas aos genes marcadores identificados
- Gerar mapas de calor, gráficos de vulcões ou outras visualizações para apresentar os genes marcadores e seus padrões de expressão
6. Validação em conjuntos de dados independentes (opcional) - Para aumentar a confiança, valide os genes marcadores identificados num conjunto de dados independente, se disponível.