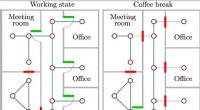
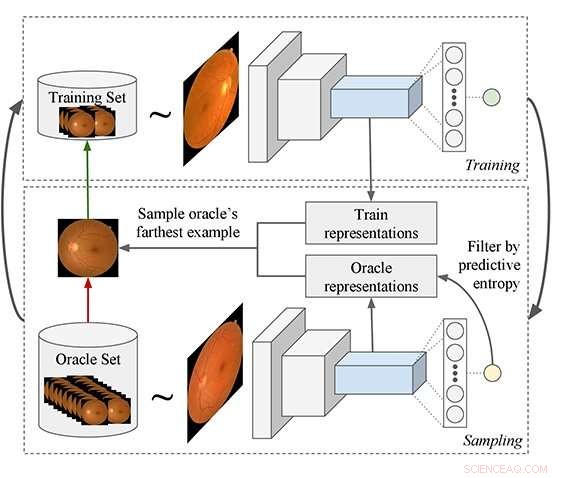
 p Pipeline de aprendizado ativo proposto:o processo começa treinando um modelo e usando-o para consultar exemplos de um conjunto de dados não rotulado que é adicionado ao conjunto de treinamento. Uma nova função de consulta é proposta, mais adequada para modelos de Deep Learning (DL). O modelo DL é usado para extrair recursos do oráculo e exemplos de conjunto de treinamento, e então o algoritmo filtra os exemplos do oráculo que têm baixa entropia preditiva. Finalmente, o exemplo oracle é selecionado que é, em média, o mais distante no espaço de recursos para todos os exemplos de treinamento. Crédito:Asim Smailagic
p Pipeline de aprendizado ativo proposto:o processo começa treinando um modelo e usando-o para consultar exemplos de um conjunto de dados não rotulado que é adicionado ao conjunto de treinamento. Uma nova função de consulta é proposta, mais adequada para modelos de Deep Learning (DL). O modelo DL é usado para extrair recursos do oráculo e exemplos de conjunto de treinamento, e então o algoritmo filtra os exemplos do oráculo que têm baixa entropia preditiva. Finalmente, o exemplo oracle é selecionado que é, em média, o mais distante no espaço de recursos para todos os exemplos de treinamento. Crédito:Asim Smailagic
p À medida que os sistemas de inteligência artificial aprendem a reconhecer e classificar melhor as imagens, eles estão se tornando altamente confiáveis no diagnóstico de doenças, como câncer de pele, a partir de imagens médicas. Mas tão bons quanto eles são na detecção de padrões, AI não substituirá seu médico tão cedo. Mesmo quando usado como uma ferramenta, sistemas de reconhecimento de imagem ainda exigem um especialista para rotular os dados, e muitos dados:ele precisa de imagens de pacientes saudáveis e doentes. O algoritmo encontra padrões nos dados de treinamento e quando recebe novos dados, ele usa o que aprendeu para identificar a nova imagem. p Um desafio é que é demorado e caro para um especialista obter e rotular cada imagem. Abordar esta questão, um grupo de pesquisadores da Faculdade de Engenharia da Carnegie Mellon University, incluindo os professores Hae Young Noh e Asim Smailagic, se uniram para desenvolver uma técnica de aprendizagem ativa que usa um conjunto de dados limitado para atingir um alto grau de precisão no diagnóstico de doenças como retinopatia diabética ou câncer de pele.
p O modelo dos pesquisadores começa a trabalhar com um conjunto de imagens não rotuladas. O modelo decide quantas imagens rotular para ter um conjunto robusto e preciso de dados de treinamento. Ele escolhe um conjunto inicial de dados aleatórios para rotular. Uma vez que os dados são rotulados, ele representa esses dados em uma distribuição porque as imagens variam com a idade, Gênero sexual, propriedade física, etc. Para tomar uma boa decisão com base nesses dados, as amostras precisam cobrir um grande espaço de distribuição. O sistema então decide quais novos dados devem ser adicionados ao conjunto de dados, considerando a distribuição atual dos dados.
p "O sistema mede o quão ótima é essa distribuição, "disse Noh, um professor associado de engenharia civil e ambiental, "e então calcula métricas quando um determinado conjunto de novos dados é adicionado a ele, e seleciona o novo conjunto de dados que maximiza sua otimização. "
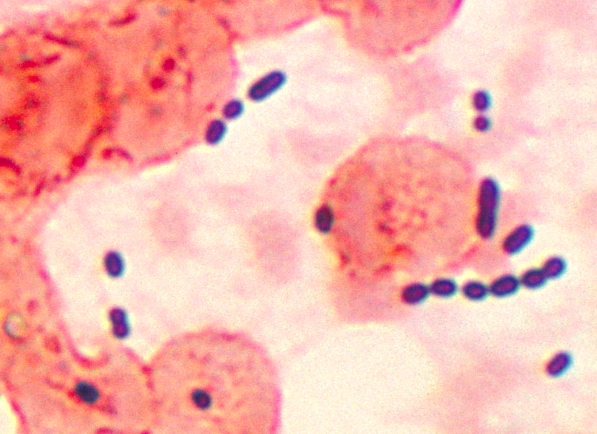
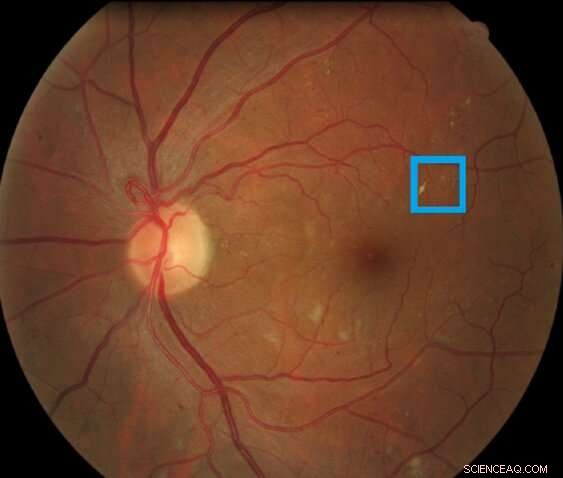 p Imagem de uma retina contendo uma lesão retiniana associada à retinopatia diabética destacada na caixa. Esse tipo de lesão é denominado microaneurisma. Crédito:Asim Smailagic
p Imagem de uma retina contendo uma lesão retiniana associada à retinopatia diabética destacada na caixa. Esse tipo de lesão é denominado microaneurisma. Crédito:Asim Smailagic
p O processo é repetido até que o conjunto de dados tenha uma distribuição boa o suficiente para ser usado como o conjunto de treinamento. Seu método, chamado MedAL (para aprendizagem ativa médica), alcançou 80% de precisão na detecção de retinopatia diabética, usando apenas 425 imagens rotuladas, que é uma redução de 32% no número de exemplos rotulados necessários em comparação com a técnica de amostragem de incerteza padrão, e uma redução de 40% em relação à amostragem aleatória.
p Eles também testaram o modelo em outras doenças, incluindo imagens de câncer de pele e de mama, para mostrar que pode ser aplicado a uma variedade de imagens médicas diferentes. O método é generalizável, já que seu foco está em como usar os dados estrategicamente, em vez de tentar encontrar um padrão ou característica específica para uma doença. Também pode ser aplicado a outros problemas que usam aprendizado profundo, mas têm restrições de dados.
p "Nossa abordagem de aprendizagem ativa combina amostragem de incerteza baseada em entropia preditiva e uma função de distância em um espaço de recurso aprendido para otimizar a seleção de amostras não rotuladas, "disse Smailagic, um professor pesquisador no Acelerador de Pesquisa em Engenharia da Carnegie Mellon. "O método supera as limitações das abordagens tradicionais, selecionando de forma eficiente apenas as imagens que fornecem mais informações sobre a distribuição geral dos dados, reduzindo o custo de computação e aumentando a velocidade e a precisão. "
p A equipe incluiu Ph.D. em engenharia civil e ambiental. alunos Mostafa Mirshekari, Jonathon Fagert, e Susu Xu, e os alunos de mestrado em engenharia elétrica e da computação Devesh Walawalkar e Kartik Khandelwal. Eles apresentaram suas descobertas na Conferência Internacional IEEE de 2018 sobre aprendizado de máquina e aplicativos em dezembro, onde receberam o prêmio de melhor artigo por seu romance.