A regressão linear é um método estatístico para examinar a relação entre uma variável dependente, denotada como y, A regressão linear é limitada a relacionamentos lineares Por sua natureza, a regressão linear só olha para relações lineares entre variáveis dependentes e independentes. Isto é, pressupõe que existe uma relação direta entre eles. Às vezes isso está incorreto. Por exemplo, a relação entre renda e idade é curva, ou seja, a renda tende a subir nas primeiras partes da vida adulta, se achatando na idade adulta e declinando depois que as pessoas se aposentam. Você pode dizer se isso é um problema, olhando representações gráficas das relações. Regressão Linear Apenas Olha para a Média da Variável Dependente Regressão Linear olha para uma relação entre a média de a variável dependente e as variáveis independentes. Por exemplo, se você observar a relação entre o peso ao nascer dos bebês e as características maternas, como a idade, a regressão linear examinará o peso médio dos bebês nascidos de mães de diferentes idades. No entanto, às vezes você precisa olhar para os extremos da variável dependente, por exemplo, bebês correm risco quando seus pesos estão baixos, então você gostaria de ver os extremos neste exemplo. Assim como a média não é uma descrição completa de uma única variável, a regressão linear não é uma descrição completa das relações entre as variáveis. Você pode lidar com esse problema usando a regressão quantílica. A regressão linear é sensível a exceções | Outliers são dados que são surpreendentes. Os outliers podem ser univariados (com base em uma variável) ou multivariados. Se você está olhando para idade e renda, outliers univariados seriam coisas como uma pessoa que tem 118 anos, ou alguém que ganhou US $ 12 milhões no ano passado. Um outlier multivariado seria um jovem de 18 anos que ganhava US $ 200.000. Nesse caso, nem a idade nem a renda são muito extremas, mas pouquíssimas pessoas de 18 anos ganham muito dinheiro. Os extremos podem ter grandes efeitos sobre a regressão. Você pode lidar com esse problema solicitando estatísticas de influência de seu software estatístico. Os dados devem ser independentes A regressão linear pressupõe que os dados são independentes. Isso significa que as pontuações de um sujeito (como uma pessoa) não têm nada a ver com as de outro. Isso é muitas vezes, mas nem sempre, sensato. Dois casos comuns em que não faz sentido são o agrupamento no espaço e no tempo. Um exemplo clássico de agrupamento no espaço são os resultados dos testes dos alunos, quando você tem alunos de várias turmas, séries, escolas e distritos escolares. Alunos da mesma turma tendem a ser parecidos em muitos aspectos, ou seja, muitas vezes vêm dos mesmos bairros, têm os mesmos professores, etc. Assim, eles não são independentes. Exemplos de agrupamento no tempo são quaisquer estudos onde você mede os mesmos assuntos várias vezes. Por exemplo, em um estudo de dieta e peso, você pode medir cada pessoa várias vezes. Esses dados não são independentes porque o que uma pessoa pesa em uma ocasião está relacionado ao que ela pesa em outras ocasiões. Uma forma de lidar com isso é com modelos multiníveis.
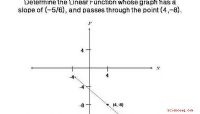
e uma ou mais variáveis independentes, denotadas como x
. A variável dependente deve ser contínua, pois pode assumir qualquer valor, ou pelo menos próximo de contínuo. As variáveis independentes podem ser de qualquer tipo. Embora a regressão linear não possa mostrar a causalidade por si só, a variável dependente é geralmente afetada pelas variáveis independentes.