Por que os métodos de aprendizado profundo reconhecem com confiança imagens que não fazem sentido
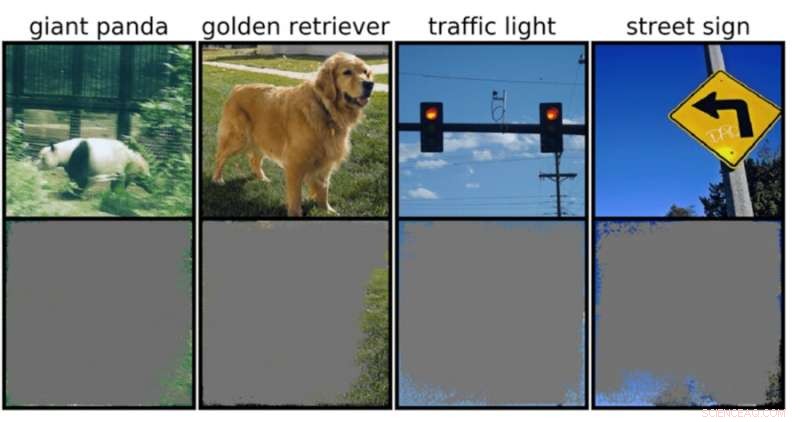
Um classificador de imagem profunda pode determinar classes de imagem com mais de 90% de confiança usando principalmente bordas de imagem, em vez de um objeto em si. Crédito:Rachel Gordon
Por tudo o que as redes neurais podem realizar, ainda não entendemos realmente como elas operam. Claro, podemos programá-los para aprender, mas dar sentido ao processo de tomada de decisão de uma máquina permanece muito parecido com um quebra-cabeça sofisticado com um padrão complexo e vertiginoso, onde muitas peças integrais ainda precisam ser encaixadas.
Se um modelo estivesse tentando classificar uma imagem do referido quebra-cabeça, por exemplo, ele poderia encontrar ataques adversários bem conhecidos, mas irritantes, ou ainda mais dados comuns ou problemas de processamento. Mas um tipo de falha novo e mais sutil recentemente identificado pelos cientistas do MIT é outro motivo de preocupação:“superinterpretação”, onde os algoritmos fazem previsões confiantes com base em detalhes que não fazem sentido para os humanos, como padrões aleatórios ou bordas de imagens.
Isso pode ser particularmente preocupante para ambientes de alto risco, como decisões em frações de segundo para carros autônomos e diagnósticos médicos para doenças que precisam de atenção mais imediata. Os veículos autônomos, em particular, dependem muito de sistemas que podem entender com precisão os arredores e, em seguida, tomar decisões rápidas e seguras. A rede usava fundos, bordas ou padrões específicos do céu para classificar semáforos e placas de rua, independentemente do que mais estivesse na imagem.
A equipe descobriu que as redes neurais treinadas em conjuntos de dados populares como CIFAR-10 e ImageNet sofriam de superinterpretação. Modelos treinados em CIFAR-10, por exemplo, fizeram previsões confiáveis mesmo quando 95% das imagens de entrada estavam faltando, e o restante não faz sentido para humanos.
"A interpretação excessiva é um problema de conjunto de dados causado por esses sinais sem sentido nos conjuntos de dados. Essas imagens de alta confiança não são apenas irreconhecíveis, mas contêm menos de 10% da imagem original em áreas sem importância, como bordas. Descobrimos que essas imagens eram sem sentido para os humanos, mas os modelos ainda podem classificá-los com alta confiança", diz Brandon Carter, Ph.D. do MIT Computer Science and Artificial Intelligence Laboratory. estudante e autor principal em um artigo sobre a pesquisa.
Os classificadores de imagem profunda são amplamente utilizados. Além do diagnóstico médico e impulsionar a tecnologia de veículos autônomos, existem casos de uso em segurança, jogos e até um aplicativo que informa se algo é ou não um cachorro-quente, porque às vezes precisamos de garantias. A tecnologia em discussão funciona processando pixels individuais de toneladas de imagens pré-rotuladas para a rede “aprender”.
A classificação de imagens é difícil, porque os modelos de aprendizado de máquina têm a capacidade de se prender a esses sinais sutis sem sentido. Então, quando os classificadores de imagem são treinados em conjuntos de dados como o ImageNet, eles podem fazer previsões aparentemente confiáveis com base nesses sinais.
Embora esses sinais sem sentido possam levar à fragilidade do modelo no mundo real, os sinais são realmente válidos nos conjuntos de dados, o que significa que a superinterpretação não pode ser diagnosticada usando métodos de avaliação típicos com base nessa precisão.
Para encontrar a justificativa para a previsão do modelo em uma determinada entrada, os métodos do presente estudo começam com a imagem completa e perguntam repetidamente:o que posso remover dessa imagem? Essencialmente, ele continua encobrindo a imagem, até que você fique com a menor peça que ainda toma uma decisão confiante.
Para o efeito, poderá também ser possível utilizar estes métodos como um tipo de critério de validação. Por exemplo, se você tiver um carro de condução autônoma que usa um método de aprendizado de máquina treinado para reconhecer sinais de parada, você pode testar esse método identificando o menor subconjunto de entrada que constitui um sinal de parada. Se isso consistir em um galho de árvore, uma determinada hora do dia ou algo que não seja um sinal de parada, você pode estar preocupado que o carro possa parar em um lugar que não deveria.
Embora possa parecer que o modelo é o provável culpado aqui, os conjuntos de dados são mais propensos a culpar. “Há a questão de como podemos modificar os conjuntos de dados de uma maneira que permita que os modelos sejam treinados para imitar mais de perto como um humano pensaria sobre a classificação de imagens e, portanto, esperamos generalizar melhor nesses cenários do mundo real, como direção autônoma. e diagnóstico médico, para que os modelos não tenham esse comportamento absurdo", diz Carter.
Isso pode significar a criação de conjuntos de dados em ambientes mais controlados. Atualmente, são apenas as fotos extraídas do domínio público que são classificadas. Mas se você quiser fazer a identificação de objetos, por exemplo, pode ser necessário treinar modelos com objetos com um background pouco informativo.