O modelo pode ser treinado em tempo real para produzir imagens de alta qualidade em apenas 12 segundos. Crédito:Bochang Moon do Instituto Gwangju de Ciência e Tecnologia, Coréia
A computação gráfica de alta qualidade, com sua presença onipresente em jogos, ilustrações e visualização, é considerada o estado da arte em tecnologia de exibição visual.
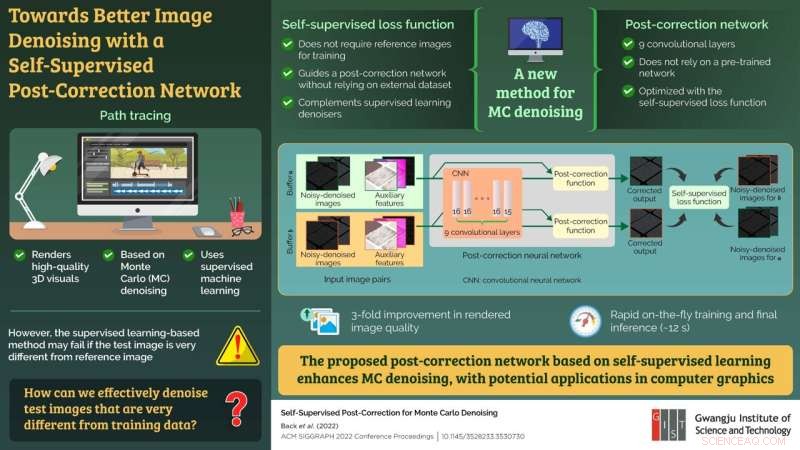
O método usado para renderizar imagens realistas e de alta qualidade é conhecido como "path tracing", que faz uso de uma abordagem de remoção de ruído de Monte Carlo (MC) baseada em aprendizado de máquina supervisionado. Nesta estrutura de aprendizado, o modelo de aprendizado de máquina é primeiro pré-treinado com pares de imagens ruidosas e limpas e, em seguida, aplicado à imagem ruidosa real a ser renderizada (imagem de teste).
Embora considerado a melhor abordagem em termos de qualidade de imagem, esse método pode não funcionar bem se a imagem de teste for marcadamente diferente das imagens usadas para treinamento.
Para resolver este problema, um grupo de pesquisadores, incluindo Ph.D. O estudante Jonghee Back e o professor associado Bochang Moon do Instituto de Ciência e Tecnologia de Gwangju na Coréia, o cientista pesquisador Binh-Son Hua da VinAI Research no Vietnã e o professor associado Toshiya Hachisuka da Universidade de Waterloo no Canadá, propuseram, em um novo estudo, um novo método de remoção de ruído MC que não depende de uma referência. Seu estudo foi disponibilizado on-line em 24 de julho de 2022 e publicado em
ACM SIGGRAPH 2022 Conference Proceedings .
"Os métodos existentes não apenas falham quando os conjuntos de dados de teste e treinamento são muito diferentes, mas também demoram muito para preparar o conjunto de dados de treinamento para pré-treinar a rede. O que é necessário é uma rede neural que possa ser treinada apenas com imagens de teste em tempo real, sem a necessidade para pré-treinamento", diz o Dr. Moon, explicando a motivação por trás de seu estudo.
Para conseguir isso, a equipe propôs uma nova abordagem pós-correção para uma imagem sem ruído que compreendia uma estrutura de aprendizado de máquina autossupervisionada e uma rede pós-correção, basicamente uma rede neural convolucional, para processamento de imagem. A rede pós-correção não dependia de uma rede pré-treinada e poderia ser otimizada usando o conceito de aprendizado autossupervisionado sem depender de uma referência. Além disso, o modelo autossupervisionado complementou e impulsionou os modelos supervisionados convencionais para denoising.
Para testar a eficácia da rede proposta, a equipe aplicou sua abordagem aos métodos de denoising de última geração existentes. O modelo proposto demonstrou uma melhoria de três vezes na qualidade da imagem renderizada em relação à imagem de entrada, preservando detalhes mais finos. Além disso, todo o processo de treinamento em tempo real e inferência final levou apenas 12 segundos.
"Nossa abordagem é a primeira que não depende de pré-treinamento usando um conjunto de dados externo. Isso, na verdade, reduzirá o tempo de produção e melhorará a qualidade do conteúdo baseado em renderização offline, como animação e filmes", diz Dr. Moon , especulando sobre as potenciais aplicações de seu trabalho.
+ Explorar mais Novo modelo de base melhora a precisão para interpretação de imagens de sensoriamento remoto














