Crédito:Google
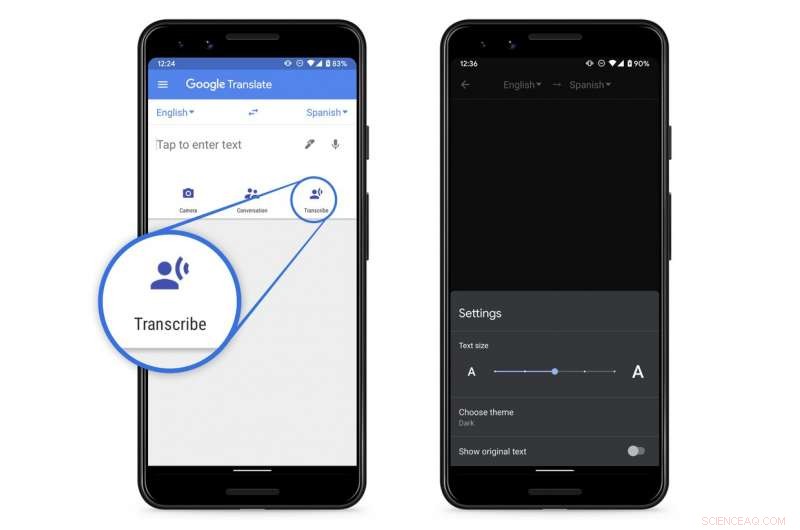
O Google anunciou um novo recurso de transcrição em tempo real para seu aplicativo Tradutor gratuito para telefones Android. Uma versão IOS está planejada para o futuro, a empresa diz.
O recurso permitirá que os usuários obtenham traduções de texto instantâneas de discursos em andamento, palestras ou monólogos em qualquer uma das oito línguas, incluindo inglês.
Atualmente, Traduzir permite conversões de apenas trechos de fala relativamente curtos.
Os únicos requisitos são ter apenas um locutor falando por vez em uma sala silenciosa (outras vozes ou ruídos diminuirão a precisão) e uma conexão com a Internet, necessário para a interação com as unidades de processamento de tensor baseadas na nuvem do Google.
O lançamento começa hoje (18 de março) e deve estar disponível para todos os usuários até o final da semana na Play Store do Google.
No modo de conversa, o aplicativo permite que os usuários tenham uma conversa de ida e volta com alguém que fala um idioma diferente.
Além do inglês, as traduções estão disponíveis em francês, Alemão, Hindi, Português, Russo, Espanhol e tailandês.
O aplicativo também funciona com reproduções de áudio pré-gravado. Mas o Google diz que a tradução digital direta dos arquivos de áudio carregados ainda não está disponível.
O anúncio desta semana é um lembrete de quão longe avançamos desde os primeiros dias do reconhecimento de voz digital. Bell Laboratories estreou seu sistema futurista "Audrey" em 1952, que reconhecia os dígitos falados de 0 a 9. Um passo gigantesco foi dado uma década depois, quando a IBM exibiu a "Shoebox" na Feira Mundial de 1962 - ela podia reconhecer incríveis 16 palavras.
Por cinco anos na década de 1970, o reconhecimento de voz recebeu um grande impulso das forças armadas da América. O Departamento de Defesa patrocinou grandes projetos de pesquisa em reconhecimento de fala, incluindo a iniciativa "Harpy" Speech Understanding Research (SUR) da Carnegie-Mellon, que construiu um vocabulário de reconhecimento de mais de 1, 011 palavras. Esse programa introduziu notavelmente o conceito de padrões de pronúncia e probabilidade pela primeira vez, aumentando muito a capacidade de reconhecer modos distintos de fala.
A década de 1980 trouxe avanços cada vez maiores na detecção de palavras, com pesquisadores aplicando a teoria da probabilidade a sons desconhecidos. O programa da gigante da tecnologia IBM expandiu o reconhecimento para 5, 000 palavras. Mas a década pode ser mais lembrada pela introdução da primeira boneca falante do mundo, "Julie, "aquele discurso compreensível. Uma campanha publicitária declarou:" Finalmente, a boneca que te entende. "
O Dragon trouxe o reconhecimento de voz para as massas na década de 1990, com seu primeiro produto de consumo bastante preciso, embora ainda cheio de bugs, com preço de "apenas" US $ 9, 000. No final da década, o programa Dragon NaturallySpeaking amplamente aprimorado, que pela primeira vez não exigiu pausas entre cada palavra falada, estava disponível para consumidores por cerca de US $ 700.
Hoje temos Siri e Alexa e outros aplicativos móveis gratuitos e de baixo custo que nos permitem solicitar instruções de direção, pedir comida, comprar utensílios domésticos e digitar texto falado em e-mails e documentos de processamento de texto, todos os quais expandiram o reconhecimento de voz para pontos inimagináveis não muitos anos atrás.
Com os avanços mais recentes disponíveis para milhões de usuários com dispositivos portáteis, Harpia, Audrey, Julie provavelmente ficaria sem palavras.
© 2020 Science X Network