
Quando o futuro é incerto, a recompensa futura pode ser representada como uma distribuição de probabilidade. alguns futuros possíveis são bons (azul-petróleo), outros são ruins (vermelho). O aprendizado por reforço distributivo pode aprender sobre essa distribuição sobre as recompensas previstas por meio de uma variante do algoritmo TD. Crédito: Natureza (2020). DOI:10.1038 / s41586-019-1924-6
Uma equipe de pesquisadores da DeepMind, A University College e a Harvard University descobriram que as lições aprendidas na aplicação de técnicas de aprendizagem aos sistemas de IA podem ajudar a explicar como as vias de recompensa funcionam no cérebro. Em seu artigo publicado na revista Natureza , o grupo descreve a comparação da aprendizagem por reforço distribucional em um computador com o processamento de dopamina no cérebro do rato, e o que aprenderam com isso.
Pesquisas anteriores mostraram que a dopamina produzida no cérebro está envolvida no processamento da recompensa - ela é produzida quando algo bom acontece, e sua expressão resulta em sensações de prazer. Alguns estudos também sugeriram que os neurônios do cérebro que respondem à presença de dopamina respondem todos da mesma maneira - um evento faz com que uma pessoa ou um camundongo se sinta bem ou mal. Outros estudos sugeriram que a resposta neuronal é mais um gradiente. Neste novo esforço, os pesquisadores encontraram evidências que apoiam a última teoria.
O aprendizado por reforço distributivo é um tipo de aprendizado de máquina baseado em reforço. É freqüentemente usado ao projetar jogos como Starcraft II ou Go. Ele acompanha os movimentos bons e os movimentos ruins e aprende a reduzir o número de movimentos ruins, melhorando seu desempenho quanto mais ele joga. Mas esses sistemas não tratam todos os movimentos bons e ruins da mesma forma - cada movimento é ponderado à medida que é registrado e os pesos são parte dos cálculos usados ao fazer futuras escolhas de movimento.
Os pesquisadores notaram que os humanos parecem usar uma estratégia semelhante para melhorar seu nível de jogo, também. Os pesquisadores em Londres suspeitaram que as semelhanças entre os sistemas de IA e a maneira como o cérebro realiza o processamento de recompensas eram provavelmente semelhantes, também. Para descobrir se eles estavam corretos, eles realizaram experimentos com camundongos. Eles inseriram dispositivos em seus cérebros que eram capazes de registrar respostas de neurônios de dopamina individuais. Os ratos foram então treinados para realizar uma tarefa na qual recebiam recompensas por responder da maneira desejada.
As respostas dos neurônios do rato revelaram que nem todos respondem da mesma maneira, como a teoria anterior havia previsto. Em vez de, eles responderam de maneiras diferentes e confiáveis - uma indicação de que os níveis de prazer que os ratos estavam experimentando eram mais parecidos com um gradiente, como a equipe havia previsto.
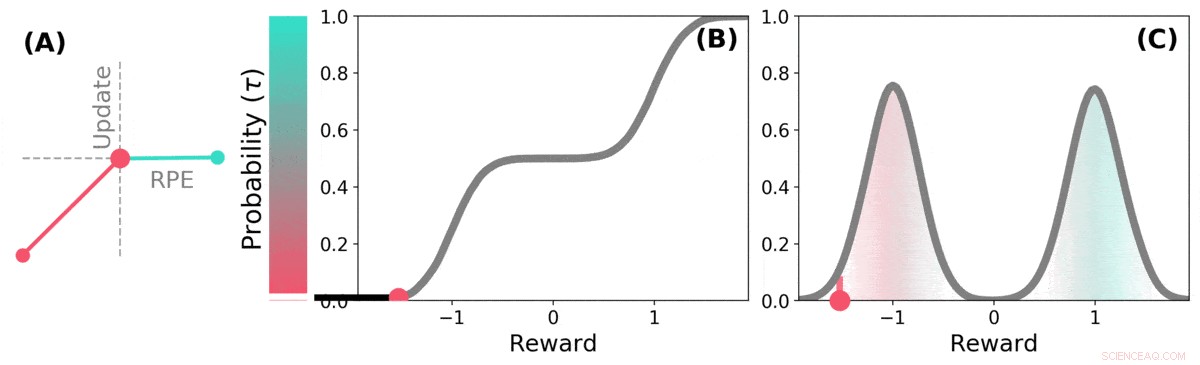
O TD distributivo aprende estimativas de valor para muitas partes diferentes da distribuição de recompensas. a parte que uma estimativa específica cobre é determinada pelo tipo de atualização assimétrica aplicada a essa estimativa. (a) Uma célula "pessimista" amplificaria atualizações negativas e ignoraria atualizações positivas, uma célula "otimista" amplificaria atualizações positivas e ignoraria atualizações negativas. (b) Isso resulta em uma diversidade de estimativas de valor pessimistas ou otimistas, mostrado aqui como pontos ao longo da distribuição cumulativa de recompensas, que capturam (c) A distribuição completa de recompensas. Crédito: Natureza (2020). DOI:10.1038 / s41586-019-1924-6
© 2020 Science X Network














