 p Crédito:Bıyık et al.
p Crédito:Bıyık et al.
p Nos últimos anos, pesquisadores têm tentado desenvolver métodos que permitam aos robôs aprender novas habilidades. Uma opção é um robô aprender essas novas habilidades com os humanos, fazer perguntas sempre que não tiver certeza de como se comportar, e aprender com as respostas do usuário humano. p Uma equipe de pesquisa da Universidade de Stanford desenvolveu recentemente uma abordagem amigável para o aprendizado ativo de recompensas que pode ser usada para treinar robôs, fazendo com que usuários humanos respondam às suas perguntas. Esta nova abordagem, apresentado em um artigo pré-publicado no arXiv, treina robôs para fazer perguntas que serão fáceis para um usuário humano responder e que não são redundantes ou desnecessárias.
p "Nosso grupo está interessado em como os robôs podem aprender o que os humanos querem, "os pesquisadores disseram ao TechXplore por e-mail." Uma maneira intuitiva de aprender é fazendo perguntas. Por exemplo, você prefere um carro autônomo que dirija cautelosamente ou agressivamente? Este carro autônomo deve se fundir na frente ou atrás de um carro movido por humanos? "
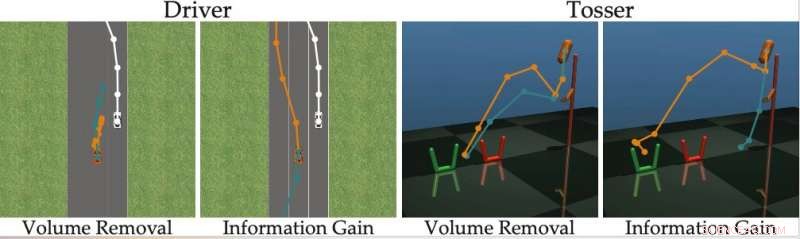
p A principal suposição por trás do estudo recente é que, idealmente, os robôs devem fazer perguntas informativas que obtenham o máximo de informações possível de usuários humanos. Em outras palavras, um robô deve ser capaz de entender o que um ser humano precisa ou deseja fazer, perguntando o mínimo possível.
p Na realidade, Contudo, a maioria das abordagens de treinamento existentes com base em respostas a perguntas não considera o quão fácil será para usuários humanos responder a perguntas específicas formuladas pelo robô. Isso geralmente resulta em usuários perdendo seu tempo respondendo a um monte de perguntas desnecessárias ou sendo incapazes de responder com certeza.
p "Descobrimos que a maioria dos algoritmos de última geração mostra as alternativas humanas que são (quase) indistinguíveis, impedindo a pessoa de responder corretamente às perguntas do robô, "disseram os pesquisadores." Voltando ao nosso exemplo, essas abordagens podem perguntar:"Você prefere se fundir na frente de um carro movido por humanos a uma velocidade de 29 mph, ou uma velocidade de 50 mph? "Isso pode ser informativo para o robô decidir se o humano deseja ir mais rápido do que 30 mph ou não, mas as opções são tão próximas que os humanos não podem responder de forma confiável. "
p Para superar as limitações dos métodos de aprendizagem ativos existentes, os pesquisadores desenvolveram um algoritmo que pode selecionar perguntas mais eficazes para fazer aos usuários humanos. O algoritmo identifica questões que mais reduzem a incerteza do robô sobre as preferências de um usuário humano (ou seja, que maximizam o ganho de informação), considerando também como será fácil para um usuário humano respondê-las.
 p Crédito:Bıyık et al.
p Crédito:Bıyık et al.
p "Inspirado nas deficiências de trabalhos anteriores, quando desenvolvemos este algoritmo, nos concentramos em levar em conta a capacidade do ser humano de realmente responder às perguntas que o robô está fazendo, ", disseram os pesquisadores." Isso se baseia na ideia de que apenas os robôs responsáveis pela capacidade de resposta do ser humano podem aprender com precisão e eficiência o que os humanos desejam. "
p Os pesquisadores calcularam o ganho de informação medindo a diminuição da entropia (ou seja, uma medida de incerteza) sobre as preferências do usuário humano em função da pergunta feita pelo robô. Em outras palavras, uma questão que maximiza o ganho de informação reduzirá a incerteza do robô sobre quais são as preferências do usuário humano. Isso dá aos robôs um objetivo formal que eles podem usar para selecionar as perguntas mais informativas.
p "Uma boa característica do ganho de informação é que ele maximiza inerentemente a incerteza do robô (de modo que o robô aprende muito com a pergunta), ao mesmo tempo que minimiza a incerteza do humano (para que a pergunta seja fácil para o humano responder), "os pesquisadores explicaram." Gerar as perguntas usando o ganho de informação melhora a aprendizagem ativa, não apenas porque as questões são informativas ao máximo, mas também porque o humano dá menos respostas erradas. "
p A abordagem concebida pelos pesquisadores avidamente seleciona a questão que maximiza o ganho de informação em cada etapa do tempo. Essencialmente, o robô mantém uma crença (ou seja, uma distribuição de probabilidade) sobre as preferências do usuário com o qual está interagindo e amostras tanto dessa crença quanto do espaço de possíveis questões.
p Em última análise, o robô escolhe a questão que fornece o maior ganho de informação na distribuição atual de possíveis preferências humanas. Subseqüentemente, ele atualiza suas crenças sobre o que o usuário deseja com base na resposta que recebe. Este processo é repetido continuamente, permitindo que o robô melhore gradualmente seu desempenho ao aprender sobre as preferências do usuário.
p "Formulamos um método computacionalmente tratável que nos permite descobrir rapidamente as preferências humanas em tarefas reais de robótica, superando métodos anteriores, "disseram os pesquisadores." Em nosso estudo, os usuários preferiram nosso método a outras técnicas de última geração. "
p Em seu estudo, a equipe baseada em Stanford mostrou que treinar um robô para fazer perguntas que maximizem o ganho de informação tem a mesma complexidade computacional dos métodos de última geração. Em outras palavras, não é mais difícil para o robô encontrar essas questões informativas, comparados aos gerados por outras abordagens.
p "Também ressaltamos que nossa abordagem tem várias propriedades matemáticas desejáveis, como submodularidade, que nos permite pegar as extensões e limites teóricos que foram desenvolvidos para abordagens anteriores e também usá-los com nosso método, "disseram os pesquisadores." Por exemplo, podemos usar trabalhos anteriores para encontrar várias questões informativas de uma vez, em vez de pesquisar uma pergunta de cada vez. "
p A equipe avaliou sua abordagem ativa de aprendizado por recompensa em uma série de simulações e descobriu que ela permite que os robôs entendam as preferências humanas com mais rapidez e precisão do que outros métodos de última geração. Isso também foi verificado em situações em que os humanos podem responder corretamente a perguntas difíceis ou quando sua resposta é "Não sei".
p Os pesquisadores também realizaram um estudo de usuário no qual pediram a participantes humanos que respondessem a perguntas geradas por seu método e outras geradas por meio de outras abordagens de última geração. O feedback que coletaram sugere que as pessoas acham as perguntas geradas por sua abordagem muito mais fáceis de responder. Além disso, users often felt that robots using the new method had acquired a more accurate representation of their preferences than they did with previously proposed approaches.
p "Considering all of our contributions together, we took a step toward enabling robots to determine human preferences, " the researchers said. "We showed that the true objective that we originally wanted the robot to maximize—-asking questions to gain as much information as possible—-can actually be solved with the same computational complexity as existing methods."
p No futuro, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. Além disso, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
p "We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively." p © 2019 Science X Network














