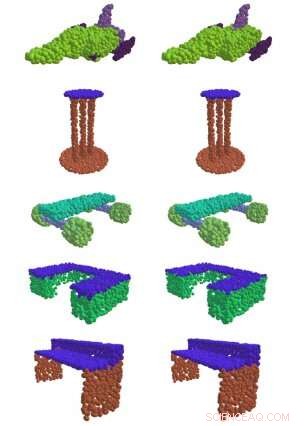
À esquerda, EdgeConv, um método desenvolvido no MIT, encontra com sucesso partes significativas de formas 3D, como a superfície de uma mesa, asas de um avião, e rodas de um skate. À direita está a comparação da verdade fundamental. Crédito:Massachusetts Institute of Technology
Se você já viu um carro autônomo em estado selvagem, você pode se perguntar sobre aquele cilindro giratório em cima dele.
É um "sensor lidar, "e é o que permite ao carro navegar pelo mundo. Enviando pulsos de luz infravermelha e medindo o tempo que leva para ricochetear nos objetos, o sensor cria uma "nuvem de pontos" que constrói um instantâneo 3-D dos arredores do carro.
É difícil entender os dados brutos da nuvem de pontos, e antes da era do aprendizado de máquina, tradicionalmente exigia que engenheiros altamente treinados especificassem tediosamente quais qualidades eles queriam capturar manualmente. Mas em uma nova série de artigos do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL), os pesquisadores mostram que podem usar o aprendizado profundo para processar nuvens de pontos automaticamente para uma ampla gama de aplicações de imagem 3D.
"Na visão computacional e no aprendizado de máquina hoje, 90 por cento dos avanços lidam apenas com imagens bidimensionais, "diz o professor Justin Solomon do MIT, que foi o autor sênior da nova série de artigos encabeçados por Ph.D. estudante Yue Wang. "Nosso trabalho visa atender a uma necessidade fundamental de representar melhor o mundo 3-D, com aplicação não apenas na direção autônoma, mas qualquer campo que requeira a compreensão de formas 3-D. "
A maioria das abordagens anteriores não teve sucesso especial em capturar os padrões de dados que são necessários para obter informações significativas de um monte de pontos 3-D no espaço. Mas em um dos papéis da equipe, eles mostraram que seu método "EdgeConv" de análise de nuvens de pontos usando um tipo de rede neural chamada rede neural convolucional de grafo dinâmico permitia classificar e segmentar objetos individuais.
“Construindo 'gráficos' de pontos vizinhos, o algoritmo pode capturar padrões hierárquicos e, portanto, inferir vários tipos de informações genéricas que podem ser usadas por uma miríade de tarefas downstream, "diz Wadim Kehl, um cientista de aprendizado de máquina no Toyota Research Institute que não estava envolvido no trabalho.
Além de desenvolver o EdgeConv, a equipe também explorou outros aspectos específicos do processamento de nuvem de pontos. Por exemplo, um desafio é que a maioria dos sensores muda de perspectiva à medida que se move pelo mundo 3-D; cada vez que fazemos uma nova verificação do mesmo objeto, sua posição pode ser diferente da última vez que o vimos. Para mesclar várias nuvens de pontos em uma única visão detalhada do mundo, você precisa alinhar vários pontos 3-D em um processo chamado "registro".
O registro é vital para muitas formas de imagem, de dados de satélite a procedimentos médicos. Por exemplo, quando um médico tem que fazer várias imagens de ressonância magnética de um paciente ao longo do tempo, o registro é o que torna possível alinhar as varreduras para ver o que mudou.
"O registro é o que nos permite integrar dados 3D de diferentes fontes em um sistema de coordenadas comum, "diz Wang." Sem ele, não seríamos realmente capazes de obter informações tão significativas de todos esses métodos que foram desenvolvidos. "
O segundo artigo de Solomon e Wang demonstra um novo algoritmo de registro chamado "Deep Closest Point" (DCP) que foi mostrado para encontrar melhor os padrões de distinção de uma nuvem de pontos, pontos, e arestas (conhecidas como "feições locais") para alinhá-las com outras nuvens de pontos. Isso é especialmente importante para tarefas como permitir que carros autônomos se situem em uma cena ("localização"), bem como para mãos robóticas para localizar e agarrar objetos individuais.
Uma limitação do DCP é que ele assume que podemos ver uma forma inteira em vez de apenas um lado. Isso significa que ele não pode lidar com a tarefa mais difícil de alinhar visualizações parciais de formas (conhecido como "registro parcial para parcial"). Como resultado, em um terceiro artigo, os pesquisadores apresentaram um algoritmo aprimorado para essa tarefa, que eles chamam de Rede de Registro Parcial (PRNet).
Solomon diz que os dados 3-D existentes tendem a ser "bastante confusos e não estruturados em comparação com imagens e fotografias 2-D". Sua equipe procurou descobrir como obter informações significativas de todos aqueles dados 3-D desorganizados sem o ambiente controlado que muitas tecnologias de aprendizado de máquina exigem agora.
Uma observação importante por trás do sucesso do DCP e PRNet é a ideia de que um aspecto crítico do processamento de nuvem de pontos é o contexto. Os recursos geométricos na nuvem de pontos A que sugerem as melhores maneiras de alinhá-la à nuvem de pontos B podem ser diferentes dos recursos necessários para alinhá-la à nuvem de pontos C. Por exemplo, em registro parcial, uma parte interessante de uma forma em uma nuvem de pontos pode não ser visível na outra - tornando-a inútil para o registro.
Wang diz que as ferramentas da equipe já foram implantadas por muitos pesquisadores na comunidade de visão computacional e além. Até os físicos estão usando-os para uma aplicação que a equipe CSAIL nunca havia considerado:física de partículas.
Seguindo em frente, os pesquisadores esperam usar os algoritmos em dados do mundo real, incluindo dados coletados de carros autônomos. Wang diz que eles também planejam explorar o potencial de treinamento de seus sistemas usando o aprendizado autossupervisionado, para minimizar a quantidade de anotação humana necessária.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.