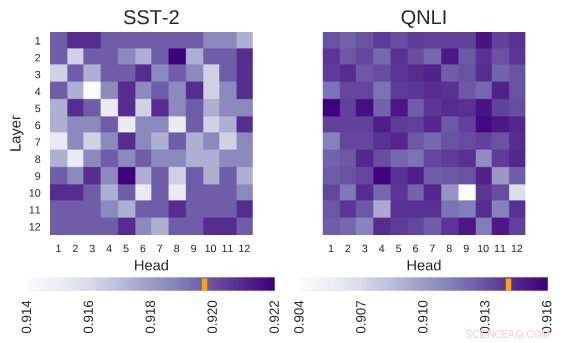
A arquitetura do BERT investigada possui a arquitetura de 12 camadas por 12 cabeçotes. Cada célula nesta figura mostra o desempenho do BERT se a cabeça correspondente for desligada. Cores mais escuras indicam melhor desempenho, e as células brancas indicam cabeças sem as quais o desempenho do BERT diminui. Stanford Sentiment Treebank (SST-2):Existem várias informações de codificação de cabeçotes que são necessárias para a tarefa. Question Natural Language Inference (QNLI):A maioria dos cabeçotes melhora o desempenho geral quando são desligados. Crédito:Kovaleva et al.
BERT, um modelo baseado em transformador caracterizado por um mecanismo único de autoatenção, até agora provou ser uma alternativa válida para redes neurais recorrentes (RNNs) na abordagem de tarefas de processamento de linguagem natural (PNL). Apesar de suas vantagens, até aqui, muito poucos pesquisadores estudaram essas arquiteturas baseadas em BERT em profundidade, ou tentaram entender as razões por trás da eficácia de seu mecanismo de autoatenção.
Ciente dessa lacuna na literatura, pesquisadores do Laboratório de Máquina de Texto Lowell da Universidade de Massachusetts para Processamento de Linguagem Natural realizaram recentemente um estudo investigando a interpretação da atenção própria, o componente mais vital dos modelos BERT. A investigadora principal e autora sênior deste estudo foram Olga Kovaleva e Anna Rumshisky, respectivamente. Seu artigo pré-publicado no arXiv e definido para ser apresentado na conferência EMNLP 2019, sugere que uma quantidade limitada de padrões de atenção são repetidos em diferentes subcomponentes de BERT, sugerindo sua sobre-parametrização.
"BERT é um modelo recente que revolucionou a comunidade de PNL, assumindo as tabelas de classificação em várias tarefas. Inspirado por esta tendência recente, estávamos curiosos para investigar como e por que funciona, "a equipe de pesquisadores disse ao TechXplore por e-mail." Esperávamos encontrar uma correlação entre auto-atenção, o principal mecanismo subjacente do BERT, e relações linguisticamente interpretáveis dentro do texto de entrada fornecido. "
As arquiteturas baseadas em BERT têm uma estrutura de camadas, e cada uma de suas camadas consiste nas chamadas "cabeças". Para o modelo funcionar, cada uma dessas cabeças é treinada para codificar um tipo específico de informação, contribuindo assim para o modelo geral à sua própria maneira. Em seu estudo, os pesquisadores analisaram as informações codificadas por essas cabeças individuais, com foco em sua quantidade e qualidade.
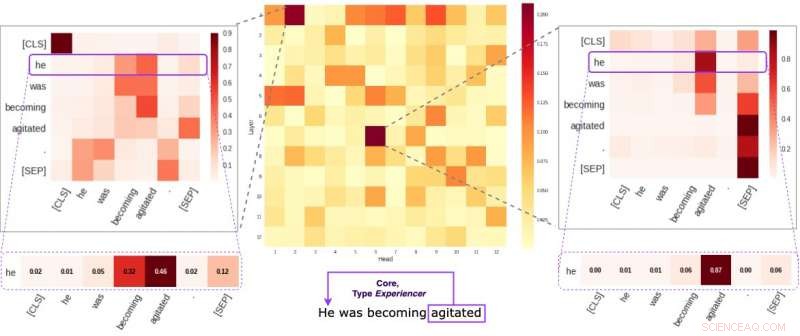
Cada célula na figura do meio reflete como as cabeças individuais prestam atenção às ligações semânticas centrais dentro de uma determinada frase (em média). Identificamos duas cabeças específicas que tendem a codificar informações semânticas mais do que as outras. As duas imagens nas laterais demonstram como essas duas cabeças atribuem pesos a palavras individuais dentro de uma frase aleatória de nosso conjunto de dados. Crédito:Kovaleva et al.
"Nossa metodologia se concentrava no exame de cabeças individuais e nos padrões de atenção que elas produziam, "os pesquisadores explicaram." Essencialmente, estávamos tentando responder à pergunta:"Quando o BERT codifica uma única palavra de uma frase, presta atenção às outras palavras de uma forma significativa para os humanos? "
Os pesquisadores realizaram uma série de experimentos usando modelos básicos de BERT pré-treinados e ajustados. Isso permitiu que eles reunissem inúmeras observações interessantes relacionadas ao mecanismo de autoatenção que está no cerne das arquiteturas baseadas em BERT. Por exemplo, eles observaram que um conjunto limitado de padrões de atenção é frequentemente repetido em diferentes cabeças, o que sugere que os modelos de BERT são parametrizados em excesso.
"Descobrimos que o BERT tende a ser parametrizado em excesso, e há muita redundância nas informações que codifica, "disseram os pesquisadores." Isso significa que a pegada computacional do treinamento de um modelo tão grande não é bem justificada. "
Outro achado interessante coletado pela equipe de pesquisadores da Universidade de Massachusetts Lowell é que, dependendo da tarefa realizada por um modelo BERT, desligar aleatoriamente algumas de suas cabeças pode levar a uma melhoria, ao invés de um declínio, no desempenho. Além disso, os investigadores não identificaram quaisquer padrões linguísticos que sejam de particular importância na determinação do desempenho do BERT em tarefas a jusante.
"Tornar o aprendizado profundo interpretável é importante para a pesquisa fundamental e aplicada, e vamos continuar trabalhando nessa direção, "disseram os pesquisadores." Novos modelos baseados em BERT foram lançados recentemente, e planejamos estender nossa metodologia para investigá-los também. "
© 2019 Science X Network














