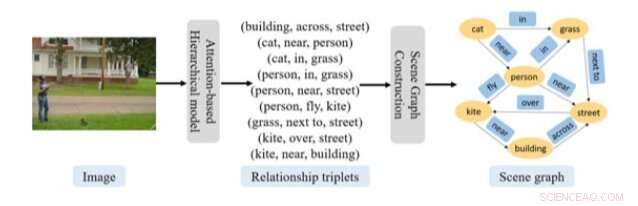
Procedimento geral de previsão de grafo de cena proposto no artigo recente. Crédito:Gao et al.
Pesquisadores da Universidade de Xangai desenvolveram recentemente uma nova abordagem baseada em redes neurais recorrentes (RNNs) para prever gráficos de cenas a partir de imagens. Sua abordagem inclui um modelo composto por dois RNNs baseados na atenção, bem como um componente de localização de entidade.
Ao longo da última década ou assim, pesquisadores da área de inteligência artificial (IA) desenvolveram uma variedade de ferramentas automáticas para gerenciar, analisar e recuperar imagens digitais. Para representar o conteúdo das imagens, as abordagens tradicionais geralmente usam palavras-chave ou recursos de visualização múltipla. Contudo, confiar em recursos ou palavras-chave geralmente leva a uma compreensão limitada das imagens, falhando em fornecer conhecimento abrangente sobre eles.
Para resolver essas deficiências, alguns anos atrás, uma equipe de pesquisadores da Universidade de Stanford, Instituto Max Planck de Informática, Yahoo Labs e Snapchat propuseram o uso de um 'grafo de cena, 'um tipo de estrutura de dados para descrever conceitos visuais em uma imagem. Os gráficos de cena podem armazenar a descrição de uma cena representada em imagens como um gráfico estruturado no qual os nós representam as informações do objeto e as bordas fornecem previsões entre dois nós.
Essas representações estruturadas podem ajudar os usuários a gerenciar imagens digitais. Contudo, prever um gráfico de cena é muitas vezes desafiador, pois requer ferramentas eficazes para reconhecer objetos, bem como seus atributos e interações entre eles.
Embora existam várias abordagens existentes para prever gráficos de cena, a maioria deles tem limitações substanciais. Em seu estudo, os pesquisadores da Universidade de Shangai decidiram desenvolver um modelo baseado em rede neural para prever gráficos de cenas de uma perspectiva orientada para a atenção visual.
"Um gráfico de cena fornece uma estrutura de conhecimento intermediária poderosa para várias tarefas visuais, incluindo recuperação de imagem semântica, legendagem de imagens, e resposta visual às perguntas, "os pesquisadores escreveram em seu artigo, que foi publicado na Wiley Online Library. "Nesse artigo, a tarefa de prever um gráfico de cena para uma imagem é formulada como dois problemas conectados, ou seja, reconhecer os trigêmeos de relacionamento, estruturado como, e construir o gráfico de cena a partir dos trigêmeos de relacionamento reconhecidos. "
A abordagem concebida por esta equipe de pesquisadores tem dois componentes principais, um visava reconhecer o que eles chamam de 'trigêmeos de relacionamento' e o outro a construir um gráfico de cena. Para reconhecer trigêmeos de relacionamento, os pesquisadores usaram um modelo composto por dois RNNs baseados na atenção em uma organização hierárquica.
"A primeira rede gera um vetor tópico para cada trio de relacionamento, enquanto a segunda rede prevê cada palavra nesse trio de relacionamento dado o vetor de tópico, "Os pesquisadores explicaram em seu artigo." Esta abordagem captura com sucesso a estrutura composicional e a dependência contextual de uma imagem e os trigêmeos de relacionamento que descrevem sua cena. "
Uma vez que este modelo baseado em RNN extraiu informações relevantes de uma imagem, o segundo componente de sua abordagem usa esses dados para construir gráficos de cena. Para esta etapa, os pesquisadores usaram uma abordagem de localização de entidade, que pode determinar a estrutura do gráfico usando as informações de atenção disponíveis. Além desses dois componentes, os pesquisadores usaram um algoritmo para esclarecer o processo por meio do qual sua abordagem converte as informações de tripletos de relacionamento geradas em um gráfico de cena.
Sua abordagem foi avaliada usando o popular conjunto de dados do genoma visual (VG) e o conjunto de dados de relacionamento visual (VRD). Para o propósito de seu estudo, os pesquisadores anotaram as imagens nesses conjuntos de dados com um conjunto de trigêmeos, rotular cada sujeito e par de objetos com informações de localização.
"Os resultados de experimentos em dois conjuntos de dados populares demonstram que a abordagem recorrente hierárquica da perspectiva orientada para a atenção visual dentro de nosso modelo tem uma melhoria distinta nos resultados em relação aos modelos de linha de base, "escreveram os pesquisadores." Em trabalhos futuros, planejamos enriquecer o grafo de cena com semântica de alto nível e atributos mais diversificados. "
© 2019 Science X Network