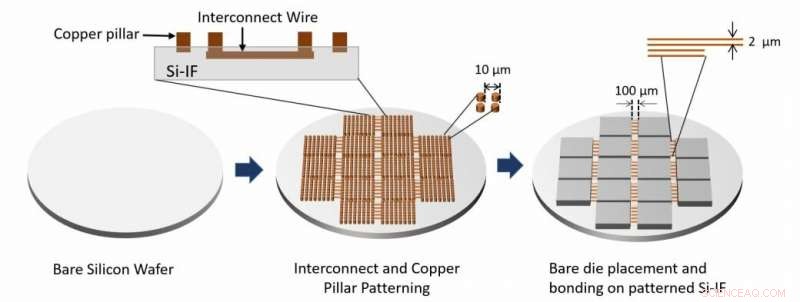
O fluxo do processo de montagem do sistema é mostrado. As camadas de interconexão e os pilares de cobre são feitos pelo processamento do wafer de silício puro. Matrizes nuas são então ligadas no wafer usando TCB. Crédito:Architecting Waferscale Processors - Um estudo de caso de GPU, HPCA 19.
Pesquisadores da Universidade de Illinois em Urbana-Champaign e da Universidade da Califórnia, Los Angeles, estão por trás do recente desenvolvimento de um computador em escala de wafer que visa ser mais rápido, mais eficiente em energia, do que as contrapartes contemporâneas.
Os engenheiros pretendem usar algo chamado "tecido de interconexão de silício" para construir um computador com 40 GPUs em um único wafer de silício. TechSpot e outros sites relataram seus trabalhos e artigos, a ser apresentado este mês.
Algumas informações sobre o Si-IF:"Nas últimas duas décadas, chips de silício diminuíram de tamanho em 1000x, enquanto os pacotes nas placas de circuito encolheram apenas 4x, "disse UCLA Technology Development Group. Uma solução é" tecido de interconexão de silício (Si-IF). "
Samuel Moore em Espectro IEEE tem um artigo muito citado sobre o tópico em que observou os resultados:"As simulações desse monstro multiprocessador aceleraram os cálculos quase 19 vezes e cortaram a combinação de consumo de energia e atraso de sinal em mais de 140 vezes."
Nomeadamente, o esforço de pesquisa está entre os membros do departamento de engenharia elétrica e da computação, Universidade da Califórnia, Los Angeles, e departamento de engenharia elétrica e informática, Universidade de Illinois em Urbana-Champaign. O artigo deles é intitulado "Architecting Waferscale Processors - A GPU Case Study".
O professor associado de engenharia da computação de Illinois, Rakesh Kumar, e seus colegas já começaram a trabalhar para construir um protótipo de sistema de processador de protótipo waferscale. O grupo irá explorá-lo mais para obter insights sobre quaisquer problemas que possam surgir. Eles acreditavam que era hora de revisitar as arquiteturas de waferscale.
Mark Tyson em Hexus :"Engenheiros da Universidade de Illinois Urbana-Champaign e da Universidade da Califórnia em Los Angeles acham que é hora de fazer outra tentativa de criar um computador em escala de wafer."
O acento pode ser colocado na palavra revisitar . A equipe escreveu em seu jornal, "Sem surpresa, os processadores waferscale foram bastante estudados nos anos 80. Houve também várias tentativas comerciais de construção de processadores waferscale. Infelizmente, apesar da promessa, tais processadores não tiveram sucesso no mercado principal devido a preocupações com o rendimento. "
Eles disseram que "quanto maior o tamanho do processador, quanto menor o rendimento - o rendimento da waferscale naquela época era debilitante. Argumentamos que avanços consideráveis na tecnologia de fabricação e embalagem foram feitos desde então e que pode ser hora de revisitar a viabilidade dos processadores waferscale. "
O professor associado de engenharia da computação de Illinois, Rakesh Kumar, e seus colaboradores estão prontos para defender um computador waferscale que consiste em até 40 GPUs. O melhor título para nos lembrar por que isso é interessante pode ser encontrado em Espectro IEEE . "O que é melhor do que 40 servidores baseados em GPU? Um servidor com 40 GPUs."
O que é especial:eles têm chips GPU padrão que passaram nos testes de qualidade - eles estão criando uma tecnologia que chamam de tecido de interconexão de silício (SiIF) para conectá-los melhor.
Shawn Knight em TechSpot escreveu sobre isso. "Com uma integração tão forte, "disse o Cavaleiro, "da perspectiva do programador, pareceria uma GPU gigante em vez de 40 GPUs individuais. "
SiIF substitui a placa de circuito por silício; não há necessidade de um pacote de chips, disse Moore. Ele relatou que em um projeto eles foram capazes de encaixar 41 GPUs. "Eles testaram uma simulação deste projeto e descobriram que ele agiliza a computação e a movimentação de dados, consumindo menos energia do que 40 servidores GPU padrão consumiriam."
Tyson escreveu que "como muitos leitores HEXUS saberão, geralmente supercomputadores espalham aplicativos por centenas de GPUs em PCBs separados, comunicação em links de longa distância. Esses links são lentos e ineficientes em termos de energia em comparação com as interconexões dentro da arquitetura do chip. ”Ele observou que Kumar falou em transferir dados de uma GPU para outra como criando uma quantidade incrível de sobrecarga.
Espectro IEEE Moore explicou seu trabalho com mais detalhes.
"O wafer de SiIF é padronizado com uma ou mais camadas de interconexões de cobre de 2 micrômetros de largura, espaçadas por apenas 4 micrômetros. Isso é comparável ao nível superior de interconexões em um chip. Nos locais onde as GPUs devem ser conectadas , o wafer de silício é padronizado com pilares de cobre curtos espaçados cerca de 5 micrômetros. A GPU está alinhada acima dessas, pressionado para baixo, e aquecido. Este processo bem estabelecido, chamada ligação por compressão térmica, faz com que os pilares de cobre se fundam às interconexões de cobre da GPU. "
Seu trabalho atraiu comentários favoráveis. Tyson considerou isso uma jogada corajosa, mas possivelmente oportuna para o setor.
Qual é o próximo? A equipe apresentará suas descobertas no IEEE International Symposium on High-Performance Computer Architecture. O evento será de 16 a 20 de fevereiro em Washington DC.
© 2019 Science X Network