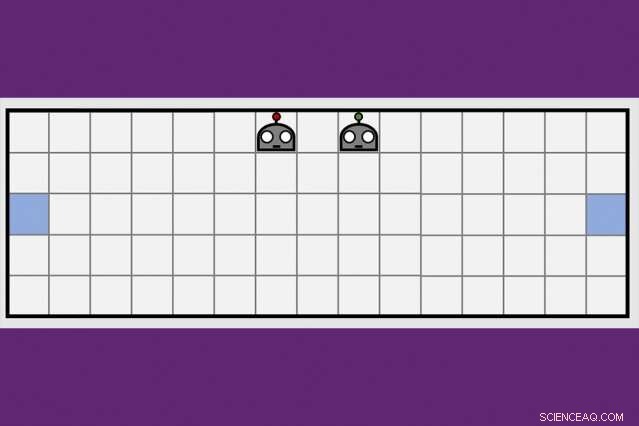
Usando uma nova técnica de aprendizagem cooperativa, Os pesquisadores do MIT-IBM Watson AI Lab reduziram pela metade o tempo que um par de agentes de robôs levava para aprender a manobrar para lados opostos de uma sala virtual. Crédito:Dong-ki Kim
Os primeiros programas de inteligência artificial para derrotar os melhores jogadores do mundo no xadrez e no jogo Go receberam pelo menos algumas instruções de humanos, e finalmente, não seria páreo para uma nova geração de programas de IA que aprendem totalmente por conta própria, por tentativa e erro.
Uma combinação de algoritmos de aprendizado profundo e aprendizado de reforço são responsáveis por computadores alcançarem o domínio em jogos de tabuleiro desafiadores, como xadrez e Go, um número crescente de videogames, incluindo a Sra. Pac-Man, e alguns jogos de cartas, incluindo pôquer. Mas para todo o progresso, os computadores ainda ficam presos quanto mais um jogo se assemelha à vida real, com informações ocultas, vários jogadores, jogo contínuo, e uma mistura de recompensas de curto e longo prazo que tornam a computação a jogada ideal extremamente complexa.
Para superar esses obstáculos, Os pesquisadores de IA estão explorando técnicas complementares para ajudar os agentes de robôs a aprender, modelado após a maneira como os humanos coletam novas informações não apenas por conta própria, mas das pessoas ao nosso redor, e de jornais, livros, e outras mídias. Uma estratégia de aprendizagem coletiva desenvolvida pelo MIT-IBM Watson AI Lab oferece uma nova direção promissora. Os pesquisadores mostram que um par de agentes robôs pode reduzir o tempo que leva para aprender uma tarefa de navegação simples em 50 por cento ou mais quando os agentes aprendem a alavancar o crescente corpo de conhecimento um do outro.
O algoritmo ensina os agentes quando pedir ajuda, e como adaptar seus conselhos ao que foi aprendido até aquele ponto. O algoritmo é único porque nenhum dos agentes é um especialista; cada um é livre para atuar como aluno-professor para solicitar e oferecer mais informações. Os pesquisadores estão apresentando seu trabalho esta semana na Conferência AAAI sobre Inteligência Artificial no Havaí.
Co-autores do artigo, que recebeu uma menção honrosa de melhor artigo de estudante na AAAI, são Jonathan como, professor do Departamento de Aeronáutica e Astronáutica do MIT; Shayegan Omidshafiei, um ex-aluno de pós-graduação do MIT agora na Alphabet's DeepMind; Dong-ki Kim do MIT; Miao Liu, Gerald Tesauro, Matthew Riemer, e Murray Campbell da IBM; e Christopher Amato da Northeastern University.
“Essa ideia de proporcionar ações que melhorem a aprendizagem do aluno, em vez de apenas dizer o que fazer, é potencialmente muito poderoso, "diz Matthew E. Taylor, um diretor de pesquisa da Borealis AI, o braço de pesquisa do Royal Bank of Canada, que não participou da pesquisa. "Embora o artigo se concentre em cenários relativamente simples, Acredito que a estrutura do aluno / professor pode ser ampliada e útil em videogames multijogador, como Dota 2, futebol de robôs, ou cenários de recuperação de desastres. "
Por enquanto, os profissionais ainda têm vantagem no Dota2, e outros jogos virtuais que favorecem o trabalho em equipe e rápido, pensamento estratégico. (Embora o braço de pesquisa de IA da Alphabet, DeepMind, recentemente virou notícia depois de derrotar um jogador profissional no jogo de estratégia em tempo real, Starcraft.) Mas, à medida que as máquinas ficam melhores na manobra de ambientes dinâmicos, eles podem em breve estar prontos para tarefas do mundo real, como gerenciar o tráfego em uma grande cidade ou coordenar equipes de busca e resgate no solo e no ar.
"As máquinas não têm o conhecimento de bom senso que desenvolvemos quando crianças, "diz Liu, um ex-pós-doutorado do MIT agora no laboratório MIT-IBM. "É por isso que eles precisam assistir a milhões de quadros de vídeo, e gastam muito tempo de computação, aprender a jogar bem. Mesmo assim, eles carecem de maneiras eficientes de transferir seu conhecimento para a equipe, ou generalizar suas habilidades para um novo jogo. Se pudermos treinar robôs para aprender com os outros, e generalizar seu aprendizado para outras tarefas, podemos começar a coordenar melhor suas interações uns com os outros, e com humanos. "
O principal insight da equipe do MIT-IBM foi que uma equipe que divide e conquista para aprender uma nova tarefa - neste caso, manobrar para extremidades opostas de uma sala e tocar a parede ao mesmo tempo - aprenderá mais rápido.
Seu algoritmo de ensino alterna entre duas fases. Em primeiro, tanto o aluno quanto o professor decidem com cada etapa respectiva se devem pedir, ou dar, conselho baseado em sua confiança de que o próximo passo, ou o conselho que estão prestes a dar, irá aproximá-los de seu objetivo. Assim, o aluno só pede conselhos, e o professor só dá, quando as informações adicionadas podem melhorar seu desempenho. A cada etapa, os agentes atualizam suas respectivas políticas de tarefas e o processo continua até que atinjam sua meta ou esgotem o tempo.
Com cada iteração, o algoritmo registra as decisões do aluno, o conselho do professor, e seu progresso de aprendizagem medido pela pontuação final do jogo. Na segunda fase, uma técnica de aprendizado por reforço profundo usa os dados de ensino registrados anteriormente para atualizar ambas as políticas de aconselhamento. "A cada atualização, o professor fica melhor em dar os conselhos certos na hora certa, "diz Kim, um estudante de pós-graduação no MIT.
Em um documento de acompanhamento a ser discutido em um workshop na AAAI, os pesquisadores aprimoram a capacidade do algoritmo de rastrear o quão bem os agentes estão aprendendo a tarefa subjacente - neste caso, uma tarefa de empurrar caixas - para melhorar a capacidade dos agentes de dar e receber conselhos. É mais uma etapa que aproxima a equipe de seu objetivo de longo prazo de entrar no RoboCup, uma competição anual de robótica iniciada por pesquisadores acadêmicos de IA.
"Precisamos escalar para 11 agentes antes de podermos jogar uma partida de futebol, "diz Tesauro, um pesquisador da IBM que desenvolveu o primeiro programa de IA para dominar o jogo de gamão. "Vai dar mais trabalho, mas estamos esperançosos."
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.