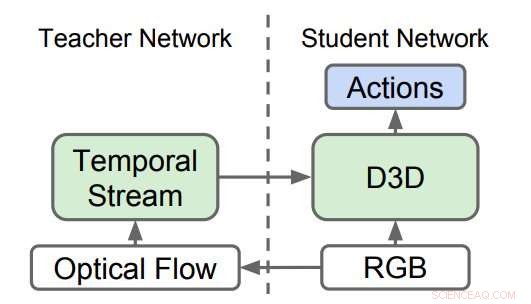
 p Redes 3D destiladas (D3D). Os pesquisadores treinaram um CNN 3D para reconhecer ações de vídeo RGB enquanto destilam conhecimento de uma rede que reconhece ações de sequências de fluxo óptico. Durante a inferência, apenas D3D é usado. Crédito:Stroud et al.
p Redes 3D destiladas (D3D). Os pesquisadores treinaram um CNN 3D para reconhecer ações de vídeo RGB enquanto destilam conhecimento de uma rede que reconhece ações de sequências de fluxo óptico. Durante a inferência, apenas D3D é usado. Crédito:Stroud et al.
p Uma equipe de pesquisadores do Google, a Universidade de Michigan e a Universidade de Princeton desenvolveram recentemente um novo método para reconhecimento de ação por vídeo. O reconhecimento de ação de vídeo envolve a identificação de ações específicas realizadas em filmagens de vídeo, como abrir uma porta, fechando uma porta, etc. p Os pesquisadores vêm tentando ensinar os computadores a reconhecer ações humanas e não humanas em vídeo há anos. A maioria das ferramentas de reconhecimento de ação de vídeo de última geração emprega um conjunto de duas redes neurais:o fluxo espacial e o fluxo temporal.
p Nessas abordagens, uma rede neural é treinada para reconhecer ações em um fluxo de imagens regulares com base na aparência (ou seja, o 'fluxo espacial') e a segunda rede é treinada para reconhecer ações em um fluxo de dados de movimento (ou seja, o 'fluxo temporal'). Os resultados obtidos por essas duas redes são então combinados para alcançar o reconhecimento de ação de vídeo.
p Embora os resultados empíricos alcançados usando abordagens de 'dois fluxos' sejam excelentes, esses métodos contam com duas redes distintas, em vez de um único. O objetivo do estudo realizado pelos pesquisadores do Google, a Universidade de Michigan e Princeton deveria investigar maneiras de melhorar isso, para substituir os dois fluxos da maioria das abordagens existentes por uma única rede que aprende diretamente com os dados.
p Nos estudos mais recentes, ambos os fluxos espaciais e temporais consistem em redes neurais convolucionais 3-D (CNNs), que aplicam filtros espaço-temporais ao videoclipe antes de tentar a classificação. Teoricamente, esses filtros temporais aplicados devem permitir que o fluxo espacial aprenda as representações de movimento, portanto, o fluxo temporal deve ser desnecessário.
p Na prática, Contudo, o desempenho das ferramentas de reconhecimento de ação de vídeo melhora quando um fluxo temporal totalmente separado é incluído. Isso sugere que o fluxo espacial sozinho é incapaz de detectar alguns dos sinais capturados pelo fluxo temporal.
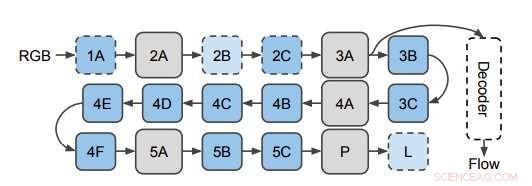 p A rede usada para prever o fluxo óptico dos recursos 3D CNN. Os pesquisadores aplicam o decodificador em camadas ocultas no CNN 3D (representado aqui na camada 3A). Este diagrama mostra a estrutura de I3D / S3D-G, onde as caixas azuis representam a convolução (linhas tracejadas) ou blocos de início (linhas sólidas), e as caixas cinza representam os blocos de pool. Os nomes das camadas são iguais aos usados no Inception. Crédito:Stroud et al.
p A rede usada para prever o fluxo óptico dos recursos 3D CNN. Os pesquisadores aplicam o decodificador em camadas ocultas no CNN 3D (representado aqui na camada 3A). Este diagrama mostra a estrutura de I3D / S3D-G, onde as caixas azuis representam a convolução (linhas tracejadas) ou blocos de início (linhas sólidas), e as caixas cinza representam os blocos de pool. Os nomes das camadas são iguais aos usados no Inception. Crédito:Stroud et al.
p Para examinar esta observação mais detalhadamente, os pesquisadores investigaram se o fluxo espacial de CNNs 3-D para reconhecimento de ação de vídeo realmente carece de representações de movimento. Subseqüentemente, eles demonstraram que essas representações de movimento podem ser melhoradas usando a destilação, uma técnica para compactar o conhecimento em um conjunto em um único modelo.
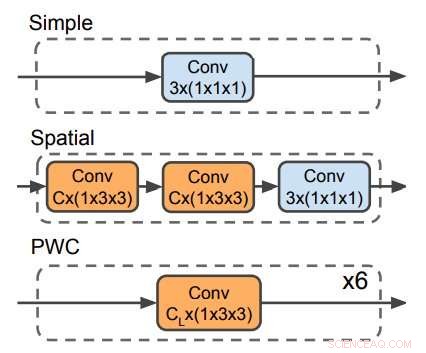 p Três decodificadores usados para prever o fluxo óptico. O decodificador PWC se assemelha à rede de previsão de fluxo óptico da rede PWC. Nenhum decodificador faz uso de filtros temporais. Crédito:Stroud et al.
p Três decodificadores usados para prever o fluxo óptico. O decodificador PWC se assemelha à rede de previsão de fluxo óptico da rede PWC. Nenhum decodificador faz uso de filtros temporais. Crédito:Stroud et al.
p Os pesquisadores treinaram uma rede de 'professores' para reconhecer ações dadas a entrada de movimento. Então, eles treinaram uma segunda rede de 'alunos', que é alimentado apenas com o fluxo de imagens regulares, com um objetivo duplo:se sair bem na tarefa de reconhecimento de ações e imitar o resultado da rede de professores. Essencialmente, a rede de alunos aprende a reconhecer com base na aparência e no movimento, melhor do que o professor e também os modelos maiores e mais complicados de dois fluxos.
p Recentemente, vários estudos também testaram uma abordagem alternativa para o reconhecimento de ação por vídeo, que envolve o treinamento de uma única rede com dois objetivos diferentes:um bom desempenho na tarefa de reconhecimento de ação e predição direta dos sinais de movimento de baixo nível (ou seja, fluxo óptico) no vídeo. Os pesquisadores descobriram que seu método de destilação superou essa abordagem. Isso sugere que é menos importante para uma rede reconhecer efetivamente o fluxo óptico de baixo nível em um vídeo do que reproduzir o conhecimento de alto nível que a rede de professores aprendeu sobre como reconhecer ações do movimento.
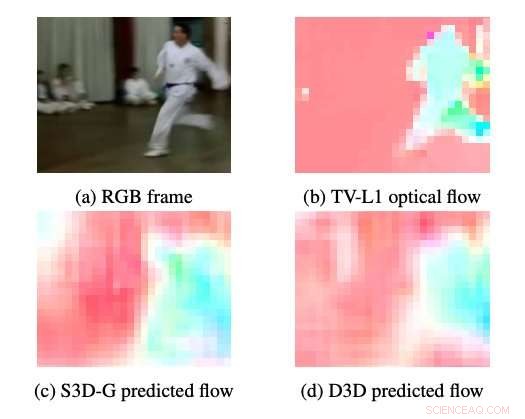 p Exemplos de fluxo óptico produzido por S3DG e D3D (sem ajuste fino) usando o decodificador PWC aplicado na camada 3A. A cor e a saturação de cada pixel correspondem ao ângulo e magnitude do movimento, respectivamente. O fluxo óptico da TV-L1 é exibido em 28 × 28px, a resolução de saída do decodificador. Crédito:Stroud et al.
p Exemplos de fluxo óptico produzido por S3DG e D3D (sem ajuste fino) usando o decodificador PWC aplicado na camada 3A. A cor e a saturação de cada pixel correspondem ao ângulo e magnitude do movimento, respectivamente. O fluxo óptico da TV-L1 é exibido em 28 × 28px, a resolução de saída do decodificador. Crédito:Stroud et al.
p Os pesquisadores provaram que é possível treinar uma rede neural de fluxo único que funciona tão bem quanto as abordagens de dois fluxos. Suas descobertas sugerem que o desempenho dos métodos atuais de última geração para reconhecimento de ação de vídeo pode ser alcançado usando aproximadamente 1/3 do cálculo. Isso tornaria mais fácil executar esses modelos em dispositivos com restrição de computação, como smartphones, e em escalas maiores (por exemplo, para identificar ações, como 'enterradas', em vídeos do YouTube).
p Geral, este estudo recente destaca algumas das deficiências dos métodos de reconhecimento de ação de vídeo existentes, propor uma nova abordagem que envolve a formação de um professor e uma rede de alunos. Pesquisa futura, Contudo, poderia tentar atingir um desempenho de ponta sem a necessidade de uma rede de professores, alimentando os dados de treinamento diretamente para a rede do aluno. p © 2019 Science X Network