O futuro da IA precisa de aceleradores de hardware baseados em dispositivos de memória analógica
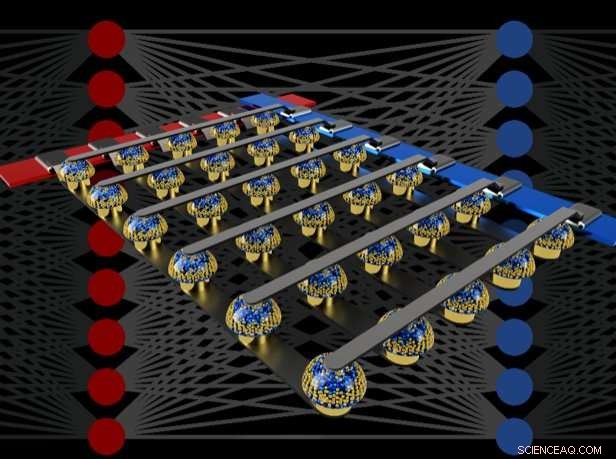 p Matrizes de barras transversais de memórias não voláteis podem acelerar o treinamento de redes neurais totalmente conectadas, executando computação no local dos dados. Crédito:IBM
p Matrizes de barras transversais de memórias não voláteis podem acelerar o treinamento de redes neurais totalmente conectadas, executando computação no local dos dados. Crédito:IBM
p Imagine Inteligência Artificial (IA) personalizada, onde seu smartphone se torna mais como um assistente inteligente - reconhecendo sua voz mesmo em uma sala barulhenta, compreender o contexto de diferentes situações sociais ou apresentar apenas as informações que são realmente relevantes para você, retirado da enxurrada de dados que chega todos os dias. Esses recursos podem em breve estar ao nosso alcance, mas chegar lá exigirá rápido, poderoso, aceleradores de hardware de IA com baixo consumo de energia. p Em um artigo recente publicado em
Natureza , nossa equipe IBM Research AI demonstrou treinamento de rede neural profunda (DNN) com grandes matrizes de dispositivos de memória analógica com a mesma precisão de um sistema baseado em unidade de processamento gráfico (GPU). Acreditamos que este seja um passo importante no caminho para o tipo de aceleradores de hardware necessários para as próximas descobertas de IA. Porque? Porque entregar o futuro da IA exigirá uma ampla expansão da escala de cálculos da IA.
p DNNs devem ficar maiores e mais rápidos, tanto na nuvem quanto no perímetro - e isso significa que a eficiência energética deve melhorar drasticamente. Embora melhores GPUs ou outros aceleradores digitais possam ajudar até certo ponto, esses sistemas inevitavelmente gastam muito tempo e energia movendo dados da memória para o processamento e vice-versa. Podemos melhorar a velocidade e a eficiência energética realizando cálculos de IA no domínio analógico com o direito na localização dos dados - mas isso só faz sentido se as redes neurais resultantes forem tão inteligentes quanto aquelas implementadas com hardware digital convencional.
p Técnicas analógicas, envolvendo sinais continuamente variáveis em vez de 0s e 1s binários, têm limites inerentes à sua precisão - razão pela qual os computadores modernos são geralmente computadores digitais. Contudo, Os pesquisadores de IA começaram a perceber que seus modelos DNN ainda funcionam bem, mesmo quando a precisão digital é reduzida a níveis que seriam muito baixos para quase qualquer outro aplicativo de computador. Assim, para DNNs, é possível que talvez a computação analógica também funcione.
p Contudo, até agora, ninguém havia provado conclusivamente que essas abordagens analógicas poderiam fazer o mesmo trabalho que o software de hoje em execução em hardware digital convencional. Isso é, Os DNNs podem realmente ser treinados para obter precisões equivalentes e altas com essas técnicas? Não adianta ser mais rápido ou mais eficiente em termos de energia no treinamento de um DNN se as precisões de classificação resultantes forem sempre inaceitavelmente baixas.
p Em nosso jornal, descrevemos como as memórias não voláteis analógicas (NVM) podem acelerar com eficiência o algoritmo de "retropropagação" no coração de muitos avanços recentes de IA. Essas memórias permitem que as operações de "multiplicação-acumulação" usadas ao longo desses algoritmos sejam paralelizadas no domínio analógico, na localização dos dados de peso, usando a física subjacente. Em vez de grandes circuitos para multiplicar e somar números digitais, simplesmente passamos uma pequena corrente através de um resistor para um fio, e, em seguida, conecte muitos desses fios para permitir que as correntes aumentem. Isso nos permite realizar muitos cálculos ao mesmo tempo, em vez de um após o outro. E em vez de enviar dados digitais em longas viagens entre chips de memória digital e chips de processamento, podemos realizar todos os cálculos dentro do chip de memória analógica.
p Contudo, devido a várias imperfeições inerentes aos dispositivos de memória analógica de hoje, as demonstrações anteriores de treinamento em DNN realizadas diretamente em grandes matrizes de dispositivos NVM reais não conseguiram atingir as precisões de classificação que correspondiam às de redes treinadas por software.
p Ao combinar o armazenamento de longo prazo em dispositivos de memória de mudança de fase (PCM), atualização quase linear de capacitores convencionais de semicondutor de óxido de metal complementar (CMOS) e novas técnicas para cancelar a variabilidade de dispositivo para dispositivo, corrigimos essas imperfeições e alcançamos precisões DNN equivalentes a software em uma variedade de redes diferentes. Esses experimentos usaram uma abordagem mista de hardware-software, combinando simulações de software de elementos de sistema que são fáceis de modelar com precisão (como dispositivos CMOS) junto com a implementação completa de hardware dos dispositivos PCM. Era essencial usar dispositivos de memória analógica real para cada peso em nossas redes neurais, porque as abordagens de modelagem para tais novos dispositivos freqüentemente falham em capturar toda a gama de variabilidade de dispositivo para dispositivo que eles podem exibir.
p Usando essa abordagem, verificamos que chips completos devem realmente oferecer precisão equivalente, e, portanto, faz o mesmo trabalho que um acelerador digital - mas mais rápido e com menor potência. Dados esses resultados encorajadores, já começamos a explorar o design de chips aceleradores de hardware protótipo, como parte de um projeto do IBM Research Frontiers Institute.
p A partir desses esforços iniciais de design, fomos capazes de fornecer, como parte do nosso artigo da Nature, estimativas iniciais para o potencial de tais chips baseados em NVM para o treinamento de camadas totalmente conectadas, em termos de eficiência energética computacional (28, 065 GOP / seg / W) e taxa de transferência por área (3,6 TOP / seg / mm2). Esses valores excedem as especificações das GPUs atuais em duas ordens de magnitude. Além disso, camadas totalmente conectadas são um tipo de camada de rede neural para a qual o desempenho real da GPU frequentemente fica bem abaixo das especificações classificadas.
p Este documento indica que nossa abordagem baseada em NVM pode fornecer precisão de treinamento equivalente a software, bem como melhorias de ordens de magnitude na aceleração e eficiência energética, apesar das imperfeições dos dispositivos de memória analógica existentes. As próximas etapas serão demonstrar essa mesma equivalência de software em redes maiores, exigindo grandes, camadas totalmente conectadas - como as redes de Long Short Term Memory (LSTM) e Gated Recurrent Unit (GRU) por trás dos avanços recentes na tradução automática, legendagem e análise de texto - e para projetar, implementar e refinar essas técnicas analógicas no protótipo de aceleradores de hardware baseados em NVM. Novas e melhores formas de memória analógica, otimizado para este aplicativo, poderia ajudar a melhorar ainda mais a densidade de área e a eficiência energética.