Esta animação mostra uma série de eventos de colisão na STAR, cada um com milhares de trilhas de partículas e os sinais registrados conforme algumas dessas partículas atingem vários componentes do detector. Deve dar uma ideia de quão complexo é o desafio de reconstruir um registro completo de cada partícula e das condições em que foi criado para que os cientistas possam comparar centenas de milhões de eventos para procurar tendências e fazer descobertas. Crédito:Laboratório Nacional de Brookhaven
Pela primeira vez, os cientistas usaram a computação de alto desempenho (HPC) para reconstruir os dados coletados por um experimento de física nuclear - um avanço que poderia reduzir drasticamente o tempo necessário para disponibilizar dados detalhados para descobertas científicas.
O projeto de demonstração usou o supercomputador Cori no National Energy Research Scientific Computing Center (NERSC), um centro de computação de alto desempenho no Laboratório Nacional Lawrence Berkeley, na Califórnia, reconstruir vários conjuntos de dados coletados pelo detector STAR durante as colisões de partículas no Relativistic Heavy Ion Collider (RHIC), uma instalação de pesquisa de física nuclear no Laboratório Nacional de Brookhaven, em Nova York. Ao executar vários trabalhos de computação simultaneamente nos núcleos de supercomputação atribuídos, a equipe transformou 4,73 petabytes de dados brutos em 2,45 petabytes de dados "prontos para a física" em uma fração do tempo que levaria usando recursos internos de computação de alto rendimento, mesmo com uma jornada de dados transcontinental de duas vias.
"A razão pela qual isso é realmente fantástico, "disse o físico de Brookhaven Jérôme Lauret, que gerencia as necessidades de computação da STAR, "é que esses recursos de computação de alto desempenho são elásticos. Você pode ligar para reservar uma grande quantidade de capacidade de computação quando precisar - por exemplo, pouco antes de uma grande conferência, quando os físicos estão com pressa para apresentar novos resultados. "De acordo com Lauret, preparar dados brutos para análise normalmente leva muitos meses, tornando quase impossível fornecer essa capacidade de resposta de curto prazo. "Mas com HPC, talvez você pudesse condensar esse tempo de produção de muitos meses em uma semana. Isso realmente fortaleceria os cientistas! "
A realização mostra as capacidades sinérgicas de RHIC e NERSC — U.S. Departamento de Energia (DOE) Instalações do usuário do Office of Science localizadas em laboratórios nacionais administrados pelo DOE em costas opostas - conectadas por uma das mais extensas redes de compartilhamento de dados de alto desempenho do mundo, Rede de Ciências de Energia do DOE (ESnet), outro recurso do DOE Office of Science.
"Este é um modelo de uso chave da computação de alto desempenho para dados experimentais, demonstrando que os pesquisadores podem fazer seu processamento de dados brutos ou campanhas de simulação em poucos dias ou semanas em um momento crítico, em vez de se espalharem ao longo de meses em seus próprios recursos dedicados, "disse Jeff Porter, membro da equipe de serviços de dados e análise da NERSC.
Bilhões de pontos de dados
Para fazer descobertas de física no RHIC, os cientistas precisam classificar centenas de milhões de colisões entre íons acelerados a uma energia muito alta. ESTRELA, um sofisticado, instrumento eletrônico do tamanho de uma casa, registra os detritos subatômicos que fluem desses esmagamentos de partículas. Nos eventos mais enérgicos, muitos milhares de partículas atingem os componentes do detector, produzindo exibições semelhantes a fogos de artifício de faixas de partículas coloridas. Mas para descobrir o que esses sinais complexos significam, e o que eles podem nos dizer sobre a forma intrigante de matéria criada nas colisões do RHIC, os cientistas precisam de descrições detalhadas de todas as partículas e das condições em que foram produzidas. Eles também devem comparar enormes amostras estatísticas de muitos tipos diferentes de eventos de colisão.
Catalogar essas informações requer algoritmos sofisticados e software de reconhecimento de padrões para combinar sinais de vários aparelhos eletrônicos de leitura, e uma maneira perfeita de combinar esses dados com os registros das condições de colisão. Todas as informações devem ser empacotadas de uma forma que os físicos possam usar para suas análises.

Cori, o mais novo supercomputador do National Energy Research Scientific Computing Center (NERSC), é um Cray XC40 com um desempenho máximo de cerca de 30 petaflops. Crédito:Laboratório Nacional de Brookhaven
Desde que o RHIC começou a funcionar no ano de 2000, este processamento de dados brutos, ou reconstrução, foi realizado em recursos de computação dedicados no RHIC e ATLAS Computing Facility (RACF) em Brookhaven. Os clusters de computação de alto rendimento (HTC) processam os dados, evento por evento, e escrever os detalhes codificados de cada colisão em um espaço de armazenamento de massa centralizado acessível aos físicos da STAR em todo o mundo.
Mas o desafio de acompanhar os dados cresceu com as taxas de colisão cada vez melhores do RHIC e à medida que novos componentes de detector foram adicionados. Nos últimos anos, Os conjuntos de dados brutos anuais da STAR atingiram bilhões de eventos com tamanhos de dados na faixa de vários petabytes. Portanto, a equipe de computação da STAR investigou o uso de recursos externos para atender à demanda por acesso oportuno a dados prontos para a física.
Muitos núcleos fazem a luz funcionar
Ao contrário dos computadores de alto rendimento do RACF, que analisam os eventos um por um, Recursos HPC como os do NERSC dividem grandes problemas em tarefas menores que podem ser executadas em paralelo. Portanto, o primeiro desafio foi "paralelizar" o processamento dos dados do evento STAR.
"Escrevemos programas de fluxo de trabalho que alcançaram o primeiro nível de paralelização - paralelização de eventos, "Lauret disse. Isso significa que eles enviam menos trabalhos feitos de muitos eventos que podem ser processados simultaneamente nos muitos núcleos de computação HPC.
“Imagine construir uma cidade com 100 casas. Se isso fosse feito de uma forma de alto rendimento, cada casa teria um construtor fazendo todas as tarefas em sequência - construir a fundação, as paredes, e assim por diante, "Lauret disse." Mas com HPC mudamos o paradigma. Em vez de um trabalhador por casa, temos 100 trabalhadores por casa, e cada trabalhador tem uma tarefa - construir as paredes ou o telhado. Eles trabalham em paralelo, ao mesmo tempo, e montamos tudo no final. Com esta abordagem, vamos construir essa casa 100 vezes mais rápido. "
Claro, é preciso alguma criatividade para pensar sobre como esses problemas podem ser divididos em tarefas que podem ser executadas simultaneamente em vez de sequencialmente, Lauret acrescentou.
O HPC também economiza tempo combinando sinais brutos do detector com dados sobre as condições ambientais durante cada evento. Para fazer isso, os computadores devem acessar um "banco de dados de condição" - um registro da voltagem, temperatura, pressão, e outras condições do detector que devem ser levadas em consideração na compreensão do comportamento das partículas produzidas em cada colisão. Em evento por evento, reconstrução de alto rendimento, os computadores acessam o banco de dados para recuperar os dados de cada evento. Mas, como os núcleos HPC compartilham alguma memória, eventos que ocorrem próximos no tempo podem usar os mesmos dados de condição armazenados em cache. Menos chamadas para o banco de dados significa processamento de dados mais rápido.
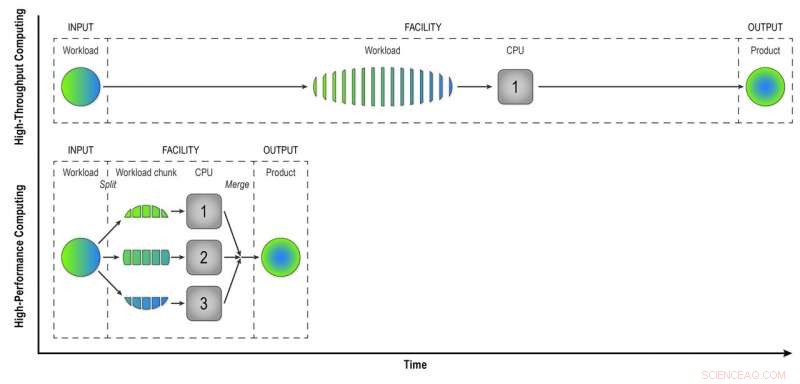
Na computação de alto rendimento, uma carga de trabalho composta de dados de muitas colisões STAR é processada evento a evento de maneira sequencial para fornecer aos físicos "dados reconstruídos" - o produto de que eles precisam para analisar completamente os dados. A computação de alto desempenho divide a carga de trabalho em pedaços menores que podem ser executados por meio de CPUs separadas para acelerar a reconstrução dos dados. Nesta ilustração simples, dividir uma carga de trabalho de 15 eventos em três blocos de cinco eventos processados em paralelo produz o mesmo produto em um terço do tempo que o método de alto rendimento. Usar 32 CPUs em um supercomputador como o Cori pode reduzir muito o tempo que leva para transformar os dados brutos de um conjunto de dados STAR real, com muitos milhões de eventos, em informações úteis que os físicos podem analisar para fazer descobertas. Crédito:Laboratório Nacional de Brookhaven
Trabalho em equipe de rede
Outro desafio na migração da tarefa de reconstrução de dados brutos para um ambiente de HPC era apenas levar os dados de Nova York para os supercomputadores na Califórnia e vice-versa. Os conjuntos de dados de entrada e saída são enormes. A equipe começou pequena, com um experimento de prova de princípio - apenas algumas centenas de tarefas - para ver como seus novos programas de fluxo de trabalho funcionariam.
"Recebemos muita assistência dos profissionais de rede de Brookhaven, "disse Lauret, "particularmente Mark Lukascsyk, um de nossos engenheiros de rede, que estava tão empolgado com a ciência e nos ajudando a fazer descobertas. "Colegas do RACF e da ESnet também ajudaram a identificar problemas de hardware e desenvolveram soluções enquanto a equipe trabalhava em estreita colaboração com Jeff Porter, Mustafa Mustafa, e outros na NERSC para otimizar a transferência de dados e o fluxo de trabalho de ponta a ponta.
Comece pequeno, escalar
Depois de ajustar seus métodos com base nos testes iniciais, a equipe começou a expandir para usar 6, 400 núcleos de computação no NERSC, então para cima e para cima e para cima.
"6, 400 núcleos já é metade do tamanho dos recursos disponíveis para reconstrução de dados no RACF, "Lauret disse." Eventualmente chegamos a 25, 600 núcleos em nosso teste mais recente. "Com tudo pronto com antecedência para uma reserva antecipada de tempo no supercomputador Cori, "Fizemos esse teste por alguns dias e concluímos toda uma produção de dados em um piscar de olhos, "Lauret disse. De acordo com Porter da NERSC, "Este modelo é potencialmente bastante transformador, e a NERSC tem trabalhado para apoiar essa utilização de recursos por, por exemplo, vinculando seu sistema de disco de alto desempenho em todo o centro diretamente à sua infraestrutura de transferência de dados e permitindo flexibilidade significativa em como os slots de trabalho podem ser programados. "
A eficiência de ponta a ponta de todo o processo - o tempo em que o programa estava em execução (não ocioso, esperando por recursos de computação) multiplicado pela eficiência de usar os slots de supercomputação atribuídos e obter saída útil todo o caminho de volta para Brookhaven - foi de 98 por cento.
"Provamos que podemos usar os recursos de HPC de forma eficiente para eliminar acúmulos de dados não processados e resolver demandas temporárias de recursos para acelerar as descobertas científicas, "Lauret disse.
Ele agora está explorando maneiras de generalizar o fluxo de trabalho para o Open Science Grid - um consórcio global que agrega recursos de computação - para que toda a comunidade de físicos nucleares e de alta energia possa fazer uso dele.