Uma estrutura de aprendizado profundo para aprimorar os recursos de um agente de esboço robótico
Crédito:Lee et al.
Nos últimos anos, algoritmos de aprendizado profundo alcançaram resultados notáveis em uma variedade de campos, incluindo disciplinas artísticas. De fato, muitos cientistas da computação em todo o mundo desenvolveram com sucesso modelos que podem criar trabalhos artísticos, incluindo poemas, pinturas e esboços.
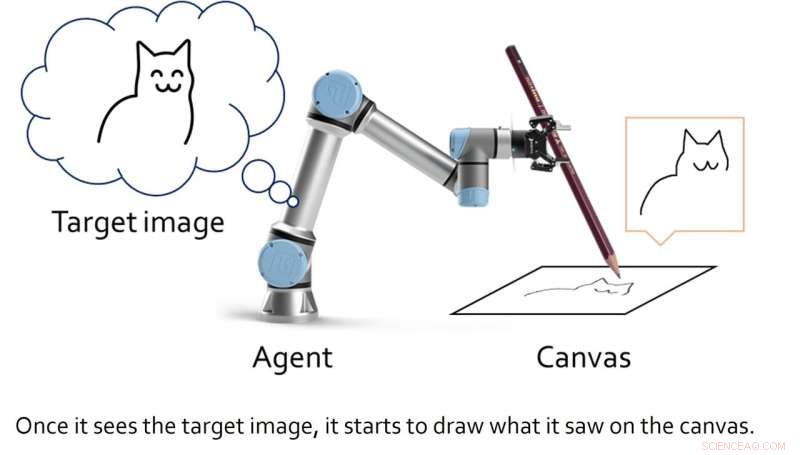
Pesquisadores da Universidade Nacional de Seul introduziram recentemente uma nova estrutura artística de aprendizado profundo, projetada para aprimorar as habilidades de um robô de esboço. Sua estrutura, apresentada em um artigo apresentado no ICRA 2022 e pré-publicado no arXiv, permite que um robô de esboço aprenda renderização baseada em traçado e controle de motor simultaneamente.
"A principal motivação para nossa pesquisa foi fazer algo legal com mecanismos não baseados em regras, como aprendizado profundo; achamos que desenhar é uma coisa legal para mostrar se o artista de desenho é um robô aprendido em vez de humano", Ganghun Lee, o primeiro autor do artigo, disse ao TechXplore. "Técnicas recentes de aprendizado profundo mostraram resultados surpreendentes na área artística, mas a maioria delas são sobre modelos generativos que produzem resultados de pixels inteiros de uma só vez."
Em vez de desenvolver um modelo generativo que produz trabalhos artísticos gerando padrões de pixels específicos, Lee e seus colegas criaram uma estrutura que representa o desenho como um processo de decisão sequencial. Esse processo sequencial se assemelha à maneira como os humanos desenham linhas individuais usando uma caneta ou lápis para criar gradualmente um esboço.
Os pesquisadores esperavam então aplicar sua estrutura a um agente de esboço robótico, para que pudesse produzir esboços em tempo real usando uma caneta ou lápis real. Enquanto outras equipes criaram algoritmos de aprendizado profundo para "artistas robôs" no passado, esses modelos normalmente exigiam grandes conjuntos de dados de treinamento contendo esboços e desenhos, bem como abordagens cinemáticas inversas para ensinar o robô a manipular uma caneta e esboçar com ela.
A estrutura criada por Lee e seus colegas, por outro lado, não foi treinada em nenhum exemplo de desenho do mundo real. Em vez disso, ele pode desenvolver autonomamente suas próprias estratégias de desenho ao longo do tempo, por meio de um processo de tentativa e erro.
“Nossa estrutura também não usa cinemática inversa, o que torna os movimentos do robô um pouco rígidos, em vez disso, também permite que o sistema encontre seus próprios truques de movimento (ajustando os valores das articulações) para tornar o estilo de movimento o mais natural possível”, disse Lee. “Em outras palavras, ele move diretamente suas articulações sem primitivas, enquanto muitos sistemas robóticos geralmente usam primitivas para se mover”.
Crédito:Lee et al.
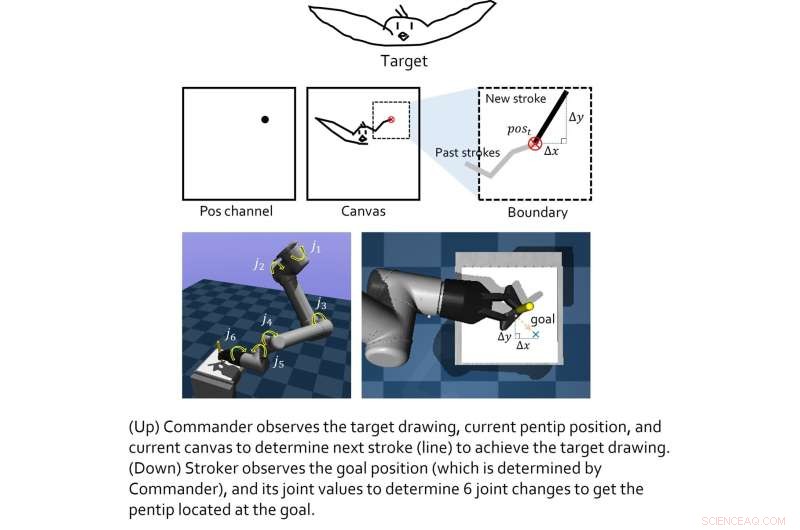
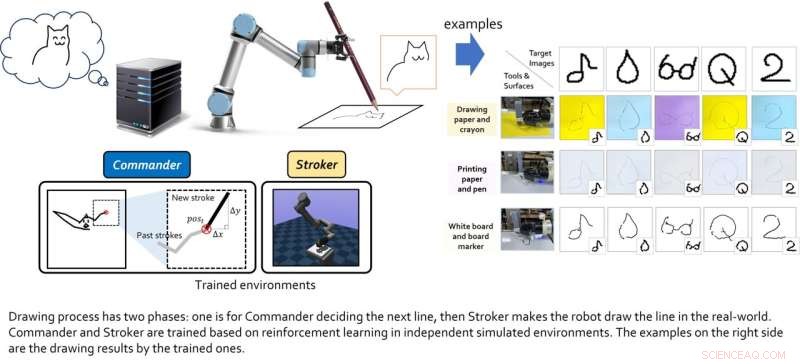
O modelo criado por esta equipa de investigadores inclui dois "agentes virtuais", nomeadamente o agente de classe alta e o agente de classe baixa. O papel do agente de classe alta é aprender novos truques de desenho, enquanto o agente de classe baixa aprende estratégias de movimento eficazes.
Os dois agentes virtuais foram treinados individualmente por meio de técnicas de aprendizado por reforço e só foram acoplados após completarem seus respectivos treinamentos. Lee e seus colegas testaram seu desempenho combinado em uma série de experimentos do mundo real, usando um braço robótico 6-DoF com uma pinça 2D nele. Os resultados alcançados nesses testes iniciais foram muito animadores, pois o algoritmo permitiu que o agente robótico produzisse bons esboços de imagens específicas.

Crédito:Lee et al.
"Descobrimos que os módulos baseados em aprendizado por reforço treinados para cada objetivo podem ser mesclados para alcançar objetivos colaborativos maiores", explicou Lee. "Em um cenário hierárquico, as decisões do agente superior podem ser o 'estado intermediário', que permite que o agente inferior observe para tomar decisões inferiores. todo o sistema feito de cada módulo pode fazer grandes coisas. No entanto, a condição primordial é que, como todas as abordagens de aprendizado por reforço têm, as funções de recompensa para cada agente devem ser bem moldadas (não é fácil)."
No futuro, a estrutura criada por Lee e seus colegas poderia ser usada para melhorar o desempenho de agentes de esboço robóticos existentes e recém-desenvolvidos. Enquanto isso, Lee está desenvolvendo modelos semelhantes baseados em aprendizado de reforço criativo, incluindo um sistema que pode produzir colagens artísticas.
Crédito:Lee et al.
"Também gostaríamos de estender a tarefa para desenhos robóticos mais complicados, como pinturas, mas agora estou focando mais nas questões práticas das aplicações de aprendizado por reforço em si do que nos desenhos robóticos", acrescentou Lee. "Espero que nosso artigo se torne um exemplo divertido e significativo de aplicativo baseado em aprendizado por reforço puro, especialmente equipado com robôs".
+ Explorar mais Uma estrutura de aprendizado por reforço para melhorar as habilidades de arremesso de futebol de robôs quadrúpedes
© 2022 Science X Network