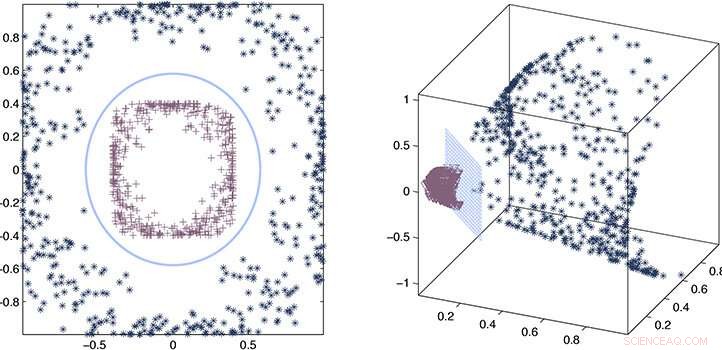
Os pesquisadores usaram um processo de estimativa de erro e aproximação matemática para provar que seu kernel aproximado permanece consistente com o kernel preciso. Crédito:2020 Ding et al.
Usando uma função "kernel" aproximada em vez de explícita para extrair relacionamentos em conjuntos de dados muito grandes, Os pesquisadores da KAUST conseguiram acelerar drasticamente a velocidade do aprendizado de máquina. A abordagem promete melhorar muito a velocidade da inteligência artificial (IA) na era dos big data.
Quando a IA é exposta a um grande conjunto de dados desconhecido, ele precisa analisar os dados e desenvolver um modelo ou função que descreva os relacionamentos no conjunto. O cálculo desta função, ou kernel, é uma tarefa de computação intensiva que aumenta em complexidade cúbica (à potência de três) com o tamanho do conjunto de dados. Na era do big data e da crescente dependência da IA para análise, isso representa um problema real em que a seleção do kernel pode se tornar impraticávelmente demorada.
Com a supervisão de Xin Gao, Lizhong Ding e seus colegas têm trabalhado em métodos para acelerar a seleção do kernel usando estatísticas.
"A complexidade computacional da seleção precisa do kernel é geralmente cúbica com o número de amostras, "diz Ding." Este tipo de escala cúbica é proibitivo para big data. Em vez disso, propusemos uma abordagem de aproximação para seleção de kernel, que melhora significativamente a eficiência da seleção do kernel sem sacrificar o desempenho preditivo. "
O kernel verdadeiro ou preciso fornece uma descrição literal dos relacionamentos no conjunto de dados. O que os pesquisadores descobriram é que as estatísticas podem ser usadas para derivar um kernel aproximado que é quase tão bom quanto a versão precisa, mas pode ser calculado muito mais rápido, escalando linearmente, ao invés de cubicamente, com o tamanho do conjunto de dados.
Para desenvolver a abordagem, a equipe teve que construir matrizes de kernel projetadas especificamente, ou matrizes matemáticas, isso pode ser calculado rapidamente. Eles também tiveram que estabelecer as regras e limites teóricos para a seleção do kernel aproximado que ainda garantiria o desempenho do aprendizado.
"O principal desafio era que precisávamos projetar novos algoritmos que satisfizessem esses dois pontos ao mesmo tempo, "diz Ding.
Combinando um processo de estimativa de erro e aproximação matemática, os pesquisadores foram capazes de provar que seu kernel aproximado permanece consistente com o kernel preciso e então demonstraram seu desempenho em exemplos reais.
"Mostramos que métodos aproximados, como nossa estrutura de computação, fornecem precisão suficiente para resolver um método de aprendizagem baseado em kernel, sem a carga computacional impraticável de métodos precisos, "diz Ding." Isso fornece uma solução eficaz e eficiente para problemas em mineração de dados e bioinformática que requerem escalabilidade. "