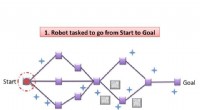
Os pesquisadores apresentam um novo algoritmo para reduzir o tempo de aprendizado de máquina
 p Crédito CC0:domínio público
p Crédito CC0:domínio público
p Uma equipe de pesquisa liderada pelo Prof. LI Huiyun dos Institutos de Tecnologia Avançada de Shenzhen (SIAT) da Academia Chinesa de Ciências introduziu um algoritmo simples de aprendizado de reforço profundo (DRL) com técnica bootstrap m-out-of-n e determinística profunda múltipla agregada estruturas de algoritmo de gradiente de política (DDPG). p Chamado "bootstrapped aggregated multi-DDPG" (BAMDDPG), o novo algoritmo acelerou o processo de treinamento e aumentou o desempenho na área de pesquisa artificial inteligente.
p Os pesquisadores testaram seu algoritmo em robô 2-D e simulador de carro de corrida aberto (TORCS). Os resultados do experimento no jogo de braço do robô 2-D mostraram que a recompensa ganha pela política agregada foi de 10% a 50% melhor do que aquela obtida por subpolíticas, e resultados de experimentos no TORCS demonstraram que o novo algoritmo pode aprender políticas de controle bem-sucedidas com menos tempo de treinamento em 56,7%.
p O algoritmo DDPG operando sobre um espaço contínuo de ações tem atraído grande atenção para o aprendizado por reforço. Contudo, a estratégia de exploração por meio de programação dinâmica dentro do espaço de estados de crença bayesiana é bastante ineficiente, mesmo para sistemas simples. Isso geralmente resulta em falha do bootstrap padrão ao aprender uma política ideal.
p O algoritmo proposto usa o buffer de replay de experiência centralizado para melhorar a eficiência da exploração. O bootstrap M-out-of-n com inicialização aleatória produz estimativas de incerteza razoáveis a baixo custo computacional, ajudando na convergência do treinamento. O DDPG inicializado e agregado proposto pode reduzir o tempo de aprendizagem.
p O BAMDDPG permite que cada agente use experiências encontradas por outros agentes. Isso torna o treinamento das subpolíticas do BAMDDPG mais eficiente, pois cada agente possui uma visão mais ampla e mais informações do ambiente.
p Este método é eficaz para os dados de treinamento sequencial e iterativo, onde os dados exibem distribuição de cauda longa, em vez da distribuição normal implicada pela suposição de dados independentes distribuídos de forma idêntica. Ele pode aprender as políticas ideais com muito menos tempo de treinamento para tarefas com espaço contínuo de ações e estados.
p O estudo, intitulado "Deep Ensemble Reforcement Learning with Multiple Deep Deterministic Policy Gradient Algorithm, "foi publicado em
Hindawi .