O robô coleta dados de interação aleatórios para serem usados para treinar uma representação e como dados fora da política para RL. Crédito:Nair et al.
O aprendizado por reforço (RL) tem se mostrado uma técnica eficaz para treinar agentes artificiais em tarefas individuais. Contudo, quando se trata de treinar robôs multifuncionais, que deve ser capaz de completar uma variedade de tarefas que requerem habilidades diferentes, a maioria das abordagens de RL existentes está longe de ser ideal.
Com isso em mente, uma equipe de pesquisadores da UC Berkeley desenvolveu recentemente uma nova abordagem de RL que pode ser usada para ensinar robôs a adaptar seu comportamento com base na tarefa com a qual são apresentados. Esta abordagem, descrito em um artigo pré-publicado no arXiv e apresentado na Conferência sobre Aprendizagem de Robôs deste ano, permite que os robôs criem comportamentos automaticamente e os pratiquem ao longo do tempo, aprender quais podem ser realizados em um determinado ambiente. Os robôs podem então redirecionar o conhecimento que adquiriram e aplicá-lo a novas tarefas que os usuários humanos pedem que eles concluam.
“Estamos convencidos de que os dados são fundamentais para a manipulação robótica e para obter dados suficientes para resolver a manipulação de uma forma geral, os robôs terão que coletar dados eles mesmos, "Ashvin Nair, um dos pesquisadores que realizou o estudo, disse TechXplore. "Isso é o que chamamos de aprendizado autossupervisionado de robôs:um robô que pode coletar ativamente dados de exploração coerentes e entender por si mesmo se teve sucesso ou falhou em tarefas para aprender novas habilidades."
A nova abordagem desenvolvida por Nair e seus colegas é baseada em uma estrutura RL condicionada a metas apresentada em seu trabalho anterior. Neste estudo anterior, os pesquisadores introduziram o estabelecimento de metas em um espaço latente como uma técnica para treinar robôs em habilidades como empurrar objetos ou abrir portas diretamente de pixels, sem a necessidade de uma função de recompensa externa ou estimativa de estado.
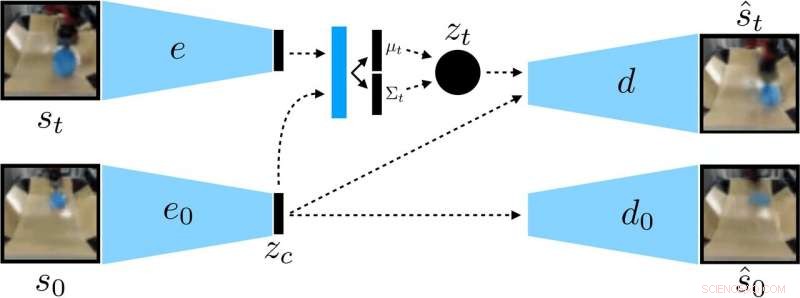
Os pesquisadores treinaram um VAE condicionado ao contexto nos dados, que desemaranha o contexto que permanece constante durante uma implementação. Crédito:Nair et al.
“Em nosso novo trabalho, nos concentramos na generalização:como podemos fazer o aprendizado autossupervisionado para não apenas aprender uma única habilidade, mas também ser capaz de generalizar para a diversidade visual enquanto executa essa habilidade? ", disse Nair." Acreditamos que a capacidade de generalizar para novas situações será a chave para uma melhor manipulação robótica. "
Em vez de treinar um robô em muitas habilidades individualmente, o modelo de definição de metas condicional proposto por Nair e seus colegas é projetado para definir metas específicas que são viáveis para o robô e estão alinhadas com seu estado atual. Essencialmente, o algoritmo que desenvolveram aprende um tipo específico de representação que separa as coisas que o robô pode controlar das coisas que não pode controlar.
Ao usar o método de aprendizagem auto-supervisionado, o robô inicialmente coleta dados (ou seja, um conjunto de imagens e ações) interagindo aleatoriamente com o ambiente circundante. Subseqüentemente, ele treina uma representação compactada desses dados que converte imagens em vetores de baixa dimensão que implicitamente contêm informações como a posição dos objetos. Em vez de ouvir explicitamente o que aprender, esta representação entende conceitos automaticamente por meio de seu objetivo de compressão.
"Usando a representação aprendida, o robô pratica alcançando objetivos diferentes e treina uma política usando aprendizagem por reforço, "Nair explicou." A representação comprimida é a chave para esta fase de prática:ela é usada para medir a proximidade de duas imagens para que o robô saiba quando teve sucesso ou falhou, e é usado para provar objetivos para o robô praticar. Na hora do teste, ele pode então corresponder a uma imagem de meta especificada por um humano, executando sua política aprendida. "
Os pesquisadores avaliaram a eficácia de sua abordagem em uma série de experimentos em que um agente artificial manipulou objetos previamente invisíveis em um ambiente criado usando a plataforma de simulação MuJuCo. Interessantemente, seu método de treinamento permitiu que o agente robótico adquirisse habilidades automaticamente que poderiam então ser aplicadas a novas situações. Mais especificamente, o robô foi capaz de manipular uma variedade de objetos, generalizando estratégias de manipulação que adquiriu anteriormente para novos objetos que não encontrou durante o treinamento.
“Estamos muito entusiasmados com dois resultados deste trabalho, "Nair disse." Primeiro, descobrimos que podemos treinar uma política para enviar objetos do mundo real em cerca de 20 objetos, mas a política aprendida pode realmente empurrar outros objetos também. Este tipo de generalização é a principal promessa dos métodos de aprendizagem profunda, e esperamos que este seja o início de formas muito mais impressionantes de generalização que virão. "
Notavelmente, em seus experimentos, Nair e seus colegas foram capazes de treinar uma política a partir de um conjunto de dados fixo de interações sem ter que coletar uma grande quantidade de dados online. Esta é uma conquista importante, como a coleta de dados para pesquisa robótica é geralmente muito cara, e ser capaz de aprender habilidades com conjuntos de dados fixos torna sua abordagem muito mais prática.
No futuro, o modelo de aprendizagem autossupervisionado desenvolvido pelos pesquisadores poderia auxiliar no desenvolvimento de robôs capazes de realizar uma ampla variedade de tarefas sem treinar um grande conjunto de habilidades individualmente. Enquanto isso, Nair e seus colegas planejam continuar testando sua abordagem em ambientes simulados, ao mesmo tempo, investigando maneiras em que poderia ser aprimorado ainda mais.
"Estamos agora desenvolvendo algumas linhas diferentes de pesquisa, incluindo a resolução de tarefas com uma quantidade muito maior de diversidade visual, bem como resolver um grande conjunto de tarefas simultaneamente e ver se somos capazes de usar a solução em uma tarefa para acelerar a resolução da próxima tarefa, "Nair disse.
© 2019 Science X Network