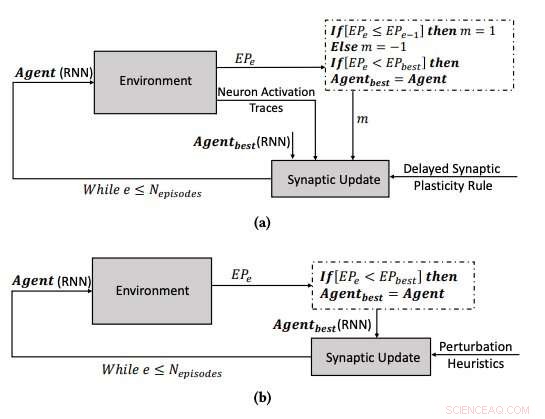
(a) O processo de aprendizagem usando a plasticidade sináptica retardada, e (b) o processo de aprendizagem por meio da otimização dos parâmetros dos RNNs usando o algoritmo de hill climbing. Crédito:Yaman et al.
O cérebro humano muda continuamente ao longo do tempo, formando novas conexões sinápticas com base em experiências e informações aprendidas ao longo da vida. Ao longo dos últimos anos, Pesquisadores de inteligência artificial (IA) têm tentado reproduzir essa capacidade fascinante, conhecido como 'plasticidade, 'em redes neurais artificiais (ANNs).
Pesquisadores da Universidade de Tecnologia de Eindhoven (Tu / e) e da Universidade de Trento propuseram recentemente uma nova abordagem inspirada em mecanismos biológicos que poderiam melhorar o aprendizado em RNAs. Seu estudo, descrito em um artigo pré-publicado no arXiv, foi financiado pelo programa de pesquisa e inovação Horizon 2020 da União Europeia.
"Uma das propriedades fascinantes das redes neurais biológicas (BNNs) é sua plasticidade, que lhes permite aprender mudando sua configuração com base na experiência, "Anil Yaman, um dos pesquisadores que realizou o estudo, disse TechXplore. "De acordo com o entendimento fisiológico atual, essas mudanças são realizadas em sinapses individuais com base nas interações locais dos neurônios. Contudo, o surgimento de um comportamento de aprendizagem global coerente a partir dessas interações individuais não é muito bem compreendido. "
Inspirado na plasticidade dos BNNs e seu processo evolutivo, Yaman e seus colegas queriam imitar mecanismos de aprendizagem biologicamente plausíveis em sistemas artificiais. Para modelar a plasticidade em RNAs, pesquisadores normalmente usam algo chamado regras de aprendizagem Hebbian, que são regras que atualizam sinapses com base em ativações neurais e sinais de reforço recebidos do ambiente.

Várias execuções independentes dos processos de aprendizagem usando várias regras evoluídas de plasticidade sináptica atrasada (a melhor regra DSP é mostrada em verde). Crédito:Yaman et al.
Quando os sinais de reforço não estão disponíveis imediatamente após cada saída de rede, Contudo, alguns problemas podem surgir, tornando mais difícil para a rede associar as ativações de neurônios relevantes ao sinal de reforço. Para superar esse problema, conhecido como o 'problema de recompensa distal, 'os pesquisadores estenderam as regras de plasticidade Hebbian para que elas possibilitassem o aprendizado em casos de recompensa distal. A abordagem deles, chamado de plasticidade sináptica retardada (DSP), usa algo chamado traços de ativação de neurônios (NATs) para fornecer armazenamento adicional em cada sinapse, bem como acompanhar as ativações dos neurônios à medida que a rede está realizando uma determinada tarefa.
"As regras de plasticidade sináptica são baseadas nas ativações locais de neurônios e um sinal de reforço, "Yaman explicou." No entanto, na maioria dos problemas de aprendizagem, os sinais de reforço são recebidos após um certo período de tempo, e não imediatamente após cada ação da rede. Nesse caso, torna-se problemático associar os sinais de reforço às ativações de neurônios. Nesse trabalho, propusemos usar o que chamamos de 'traços de ativação de neurônios, 'para armazenar as estatísticas de ativações de neurônios em cada sinapse e informar as regras de plasticidade sináptica sobre como realizar mudanças sinápticas atrasadas. "
Um dos aspectos mais significativos da abordagem desenvolvida por Yaman e seus colegas é que ela não assume informações globais sobre o problema que a rede neural estará resolvendo. Além disso, não depende da arquitetura específica da RNA e, portanto, é altamente generalizável.
"Em termos práticos, nosso estudo pode estabelecer a base para novos esquemas de aprendizagem que podem ser usados em uma série de aplicações de redes neurais, como robótica e veículos autônomos, e, em geral, em todos os casos em que um agente deve realizar um comportamento adaptativo na ausência de uma recompensa imediata obtida por suas ações, "Giovanni Iacca, outro pesquisador envolvido no estudo, disse TechXplore. "Por exemplo, em IA para videogame, uma ação no intervalo de tempo atual pode não necessariamente levar a uma recompensa agora, mas só depois de algum tempo; um agente que mostra anúncios personalizados pode receber uma "recompensa" pelo comportamento do usuário somente depois de algum tempo, etc.). "
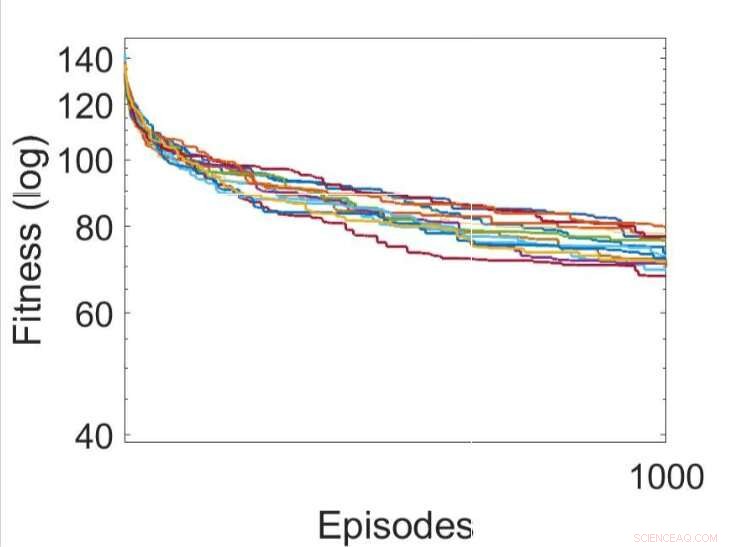
Várias execuções independentes dos processos de aprendizagem, otimizando os parâmetros dos RNNs usando o algoritmo de hill climbing. Crédito:Yaman et al.
Os pesquisadores testaram suas regras de plasticidade Hebbian recentemente adaptadas em uma simulação de um ambiente de labirinto em T triplo. Neste ambiente, um agente controlado por uma rede neural recorrente simples (RNN) precisa aprender a encontrar uma entre oito posições de objetivo possíveis, a partir de uma configuração de rede aleatória.
Yaman, Iacca e seus colegas compararam o desempenho alcançado usando sua abordagem com aquele obtido quando um agente foi treinado usando um algoritmo de busca local iterativo análogo, chamado hill climbing (HC). A principal diferença entre o algoritmo de escalada HC e sua abordagem é que o primeiro não usa nenhum conhecimento de domínio (ou seja, ativações locais de neurônios), enquanto o último faz.
Os resultados coletados pelos pesquisadores sugerem que as atualizações sinápticas realizadas por suas regras de DSP levam a um treinamento mais eficaz e, em última análise, a um desempenho melhor do que o algoritmo HC. No futuro, sua abordagem pode ajudar a melhorar o aprendizado de longo prazo em RNAs, permitindo que sistemas artificiais construam efetivamente novas conexões com base em suas experiências.
"Estamos principalmente interessados em compreender o comportamento emergente e a dinâmica de aprendizagem de redes neurais artificiais, e desenvolver um modelo coerente para explicar como a plasticidade sináptica ocorre em diferentes cenários de aprendizagem, "Yaman disse." Eu acho que há grandes possibilidades para pesquisas futuras nesta área, por exemplo, será interessante dimensionar a abordagem proposta para problemas complexos de grande escala (bem como redes profundas) e obter mecanismos de aprendizagem de inspiração biológica que requeiram o mínimo de supervisão (ou mesmo nenhuma). "
© 2019 Science X Network