Crédito:IBM
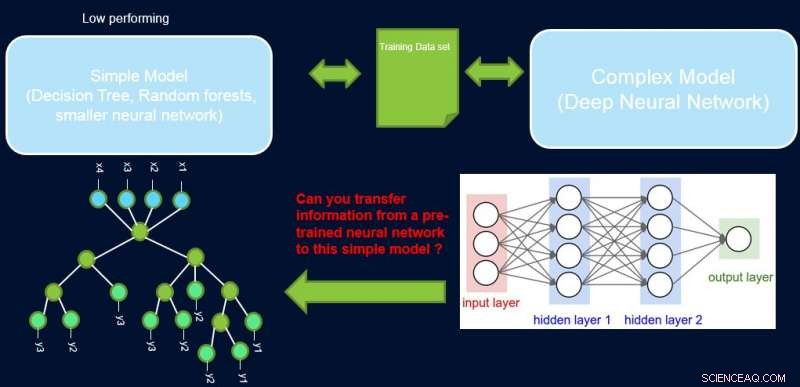
A interpretabilidade e o desempenho de um sistema estão geralmente em conflito um com o outro, pois muitos dos modelos de melhor desempenho (a saber, redes neurais profundas) são de natureza caixa-preta. Em nosso trabalho, Melhorando Modelos Simples com Perfis de Confiança, tentamos preencher essa lacuna propondo um método para transferir informações de uma rede neural de alto desempenho para outro modelo que o especialista no domínio ou a aplicação possa exigir. Por exemplo, em biologia computacional e economia, modelos lineares esparsos são frequentemente preferidos, enquanto em domínios instrumentados complexos, como fabricação de semicondutores, os engenheiros podem preferir usar árvores de decisão. Esses modelos interpretáveis mais simples podem construir a confiança do especialista e fornecer uma visão útil que leva à descoberta de fatos novos e até então desconhecidos. Nossa meta é ilustrada abaixo, para um caso específico em que estamos tentando melhorar o desempenho de uma árvore de decisão.
O pressuposto é que nossa rede é um professor de alto desempenho, e podemos usar algumas de suas informações para ensinar o simples, interpretável, mas geralmente modelo de aluno de baixo desempenho. Ponderar as amostras por sua dificuldade pode ajudar o modelo simples a se concentrar em amostras mais fáceis que ele pode modelar com sucesso durante o treinamento, e assim obter um melhor desempenho geral. Nossa configuração é diferente de impulsionar:nessa abordagem, exemplos difíceis com respeito a um aluno anterior 'fraco' são destacados para treinamento subsequente para criar diversidade. Aqui, exemplos difíceis dizem respeito a um modelo complexo preciso. Isso significa que esses rótulos são quase aleatórios. Além disso, se um modelo complexo não puder resolver isso, há pouca esperança para o modelo simples de complexidade fixa. Portanto, é importante em nossa configuração destacar exemplos fáceis que o modelo simples pode resolver.
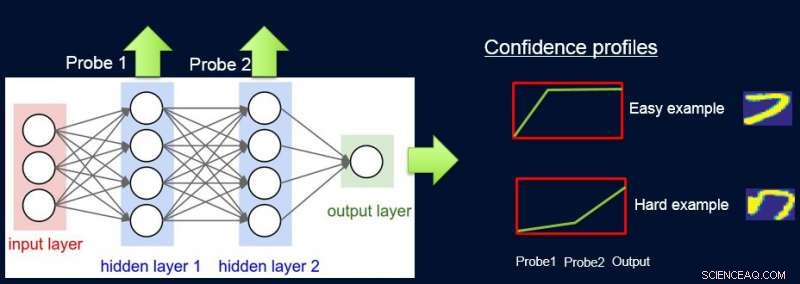
Para fazer isso, atribuímos pesos às amostras de acordo com a dificuldade da rede em classificá-las, e fazemos isso introduzindo sondas. Cada teste obtém sua entrada de uma das camadas ocultas. Cada ponta de prova possui uma única camada totalmente conectada com uma camada softmax do tamanho da saída de rede anexada a ela. A sonda na camada i serve como um classificador que usa apenas o prefixo da rede até a camada i. A suposição é que as instâncias fáceis serão classificadas corretamente com alta confiança, mesmo com sondas de primeira camada, e assim obtemos níveis de confiança p eu de todas as análises para cada uma das instâncias. Usamos todos os p eu calcular a dificuldade da instância w eu , por exemplo. como a área sob a curva (AUC) de p eu 's.
Agora podemos usar os pesos para treinar novamente o modelo simples no conjunto de dados final ponderado. Chamamos esse pipeline de sondagem, obtenção de pesos de confiança, e retreinar o ProfWeight.
Crédito:IBM
Apresentamos duas alternativas de como calculamos pesos para exemplos no conjunto de dados. Na abordagem AUC mencionada acima, observamos o erro / precisão de validação do modelo simples quando treinado no conjunto de treinamento original. Selecionamos sondas que têm uma precisão de pelo menos α (> 0) maior que o modelo simples. Cada exemplo é ponderado com base na pontuação de confiança média para o rótulo verdadeiro que é calculado usando as previsões suaves individuais das sondas.
Uma segunda alternativa envolve a otimização usando uma rede neural. Aqui, aprendemos os pesos ideais para o conjunto de treinamento, otimizando o seguinte objetivo:
S * =min C min β E [λ (Swβ (x), y)], sub. para. E [w] =1
onde w são os pesos a serem encontrados para cada instância, β denota o espaço de parâmetros do modelo simples S, e λ é sua função de perda. Precisamos restringir os pesos, visto que, caso contrário, a solução trivial de todos os pesos indo para zero será ótima para o objetivo acima. Mostramos no artigo que nossa restrição de E [w] =1 tem uma conexão para encontrar a amostragem de importância ótima.
Crédito:IBM
De forma mais geral, o ProfWeight pode ser usado para transferir para modelos ainda mais simples, mas opacos, como redes neurais menores, que pode ser útil em domínios com severas restrições de memória e poder. Essas restrições são experimentadas ao implantar modelos em dispositivos de borda em sistemas IoT ou em dispositivos móveis ou em veículos aéreos não tripulados.
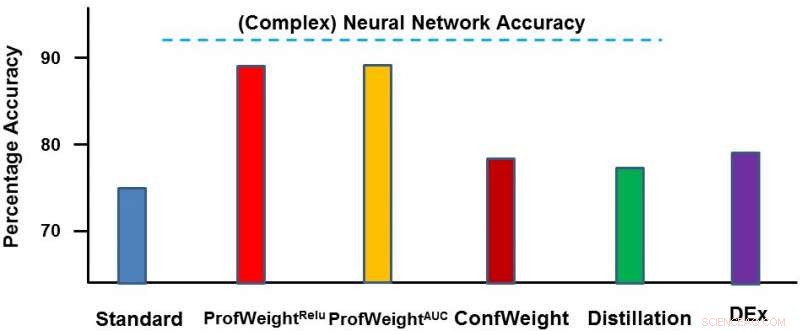
Testamos nosso método em dois domínios:um conjunto de dados de imagens públicas CIFAR-10 e um conjunto de dados de manufatura proprietário. No primeiro conjunto de dados, nossos modelos simples eram redes neurais menores que obedeciam a restrições rígidas de memória e energia e onde vimos uma melhoria de 3 a 4%. No segundo conjunto de dados, nosso modelo simples era uma árvore de decisão e o melhoramos significativamente em cerca de 13 por cento, que levou a resultados acionáveis pelo engenheiro. Abaixo, representamos o ProfWeight em comparação com os outros métodos neste conjunto de dados. Observamos aqui que superamos os outros métodos por alguma margem.
No futuro, gostaríamos de encontrar as condições necessárias / suficientes quando a transferência pela nossa estratégia resultasse no aprimoramento de modelos simples. Gostaríamos também de desenvolver métodos mais sofisticados de transferência de informações do que já realizamos.
Apresentaremos este trabalho em um artigo intitulado "Melhorando Modelos Simples com Perfis de Confiança" na Conferência de 2018 sobre Sistemas de Processamento de Informação Neural, na quarta-feira, 5 de dezembro, durante a sessão de pôsteres à noite, das 17h às 19h, na sala 210 e 230 AB (# 90).
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.














