Um modelo de aprendizado profundo leve e preciso para o reconhecimento audiovisual de emoções
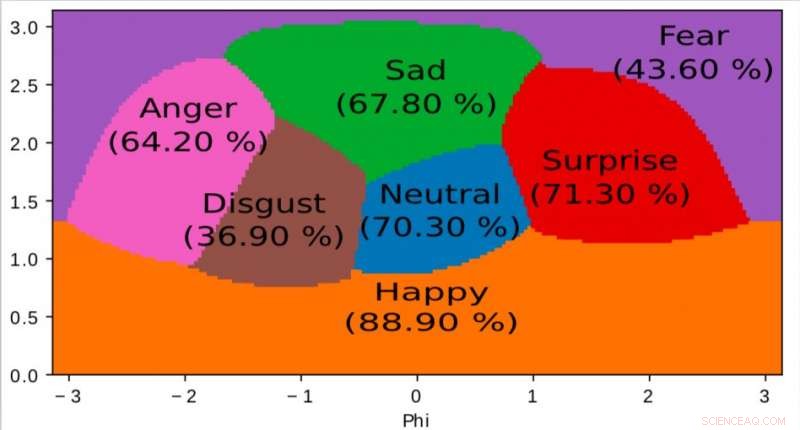 p Uma representação do espaço interno aprendido por nosso algoritmo e usado para mapear emoções em um espaço 2D contínuo. É interessante notar que, mesmo que os dados de treinamento contenham apenas rótulos emocionais discretos, a rede aprende um espaço contínuo, permitindo não apenas descrever com precisão o estado emocional das pessoas, mas também posicionar as emoções em relação umas às outras. Este espaço tem grande semelhança com o espaço de valência de excitação definido pela psicologia moderna. Crédito:Jurie et al.
p Uma representação do espaço interno aprendido por nosso algoritmo e usado para mapear emoções em um espaço 2D contínuo. É interessante notar que, mesmo que os dados de treinamento contenham apenas rótulos emocionais discretos, a rede aprende um espaço contínuo, permitindo não apenas descrever com precisão o estado emocional das pessoas, mas também posicionar as emoções em relação umas às outras. Este espaço tem grande semelhança com o espaço de valência de excitação definido pela psicologia moderna. Crédito:Jurie et al.
p Pesquisadores do Orange Labs e da Normandie University desenvolveram um novo modelo neural profundo para o reconhecimento audiovisual de emoções que funciona bem com pequenos conjuntos de treinamento. Seu estudo, que foi pré-publicado em
arXiv , segue uma filosofia de simplicidade, limitando substancialmente os parâmetros que o modelo adquire de conjuntos de dados e usando técnicas de aprendizagem simples. p As redes neurais para reconhecimento de emoções têm uma série de aplicações úteis dentro dos contextos da saúde, análise do cliente, vigilância, e até animação. Embora algoritmos de aprendizado profundo de última geração tenham alcançado resultados notáveis, a maioria ainda é incapaz de alcançar a mesma compreensão das emoções alcançadas pelos humanos.
p "Nosso objetivo geral é facilitar a interação humano-computador, tornando os computadores capazes de perceber vários detalhes sutis expressos por humanos, "Frédéric Jurie, um dos pesquisadores que realizou o estudo, disse TechXplore. “Percebendo emoções contidas nas imagens, vídeo, voz e som se enquadram neste contexto. "
p Recentemente, estudos reuniram conjuntos de dados multimodais e temporais que contêm vídeos anotados e clipes audiovisuais. No entanto, esses conjuntos de dados normalmente contêm um número relativamente pequeno de amostras anotadas, enquanto tem um bom desempenho, a maioria dos algoritmos de aprendizado profundo existentes exige conjuntos de dados maiores.
p Os pesquisadores tentaram resolver esse problema desenvolvendo uma nova estrutura para o reconhecimento de emoções audiovisuais, que funde a análise de imagens visuais e de áudio, retendo um alto nível de precisão, mesmo com conjuntos de dados de treinamento relativamente pequenos. Eles treinaram seu modelo neural em AFEW, um conjunto de dados de 773 clipes audiovisuais extraídos de filmes e anotados com emoções discretas.
 p Ilustração de como este espaço 2D pode ser usado para controlar emoções expressas por rostos, de forma contínua, com a ajuda de redes gerativas adversárias (GAN). Crédito:Jurie et al.
p Ilustração de como este espaço 2D pode ser usado para controlar emoções expressas por rostos, de forma contínua, com a ajuda de redes gerativas adversárias (GAN). Crédito:Jurie et al.
p "Pode-se ver este modelo como uma caixa preta processando o vídeo e inferindo automaticamente o estado emocional das pessoas, "Jurie explicou." Uma grande vantagem desses modelos neurais profundos é que eles aprendem sozinhos como processar o vídeo analisando exemplos, e não exigem especialistas para fornecer unidades de processamento específicas. "
p O modelo idealizado pelos pesquisadores segue o princípio filosófico da navalha de Occam, o que sugere que entre duas abordagens ou explicações, o mais simples é a melhor escolha. Ao contrário de outros modelos de aprendizagem profunda para reconhecimento de emoções, Portanto, seu modelo é relativamente simples. A rede neural aprende um número limitado de parâmetros do conjunto de dados e emprega estratégias básicas de aprendizagem.
p "A rede proposta é feita de camadas de processamento em cascata abstraindo as informações, do sinal à sua interpretação, "Jurie disse." Áudio e vídeo são processados por dois canais diferentes da rede e são combinados recentemente no processo, quase no final. "
p Quando testado, seu modelo de luz alcançou uma precisão promissora de reconhecimento de emoção de 60,64 por cento. Também ficou em quarto lugar no desafio Emotion Recognition in the Wild (EmotiW) 2018, realizada na Conferência Internacional ACM sobre Interação Multimodal (ICMI), no Colorado.
 p Ilustração de como este espaço 2D pode ser usado para controlar emoções expressas por rostos, de forma contínua, com a ajuda de redes gerativas adversárias (GAN). Crédito:Jurie et al.
p Ilustração de como este espaço 2D pode ser usado para controlar emoções expressas por rostos, de forma contínua, com a ajuda de redes gerativas adversárias (GAN). Crédito:Jurie et al.
p “Nosso modelo é a prova de que seguindo o princípio da navalha de Occam, ou seja, sempre escolhendo as alternativas mais simples para projetar redes neurais, é possível limitar o tamanho dos modelos e obter redes neurais muito compactas, mas de última geração, que são mais fáceis de treinar, "Jurie disse." Isso contrasta com a tendência de pesquisa de tornar as redes neurais cada vez maiores. "
p Os pesquisadores agora continuarão a explorar maneiras de alcançar alta precisão no reconhecimento de emoções, analisando simultaneamente dados visuais e auditivos, usando os conjuntos de dados de treinamento anotados limitados que estão disponíveis atualmente.
p "Estamos interessados em várias direções de pesquisa, como a melhor forma de fundir as diferentes modalidades, como representar emoção compactando semanticamente significando descritores completos (e não apenas rótulos de classe) ou como tornar nossos algoritmos capazes de aprender com menos, ou mesmo sem, dados anotados, "Jurie disse. p © 2018 Tech Xplore