Uma abordagem de aprendizado de reforço profundo sem modelo para lidar com problemas de controle neural
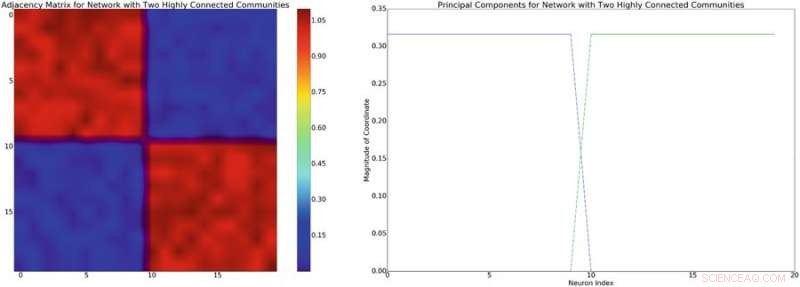 p Esquerda:exemplo de uma matriz de adjacência com estrutura bloco-diagonal aproximada. Supondo um modelo de mistura linear de interações neuronais, esta estrutura de rede irá induzir uma covariância diagonal de blocos de estrutura semelhante. À direita:os componentes principais associados à matriz de adjacência à esquerda. Crédito:Mitchell &Petzold
p Esquerda:exemplo de uma matriz de adjacência com estrutura bloco-diagonal aproximada. Supondo um modelo de mistura linear de interações neuronais, esta estrutura de rede irá induzir uma covariância diagonal de blocos de estrutura semelhante. À direita:os componentes principais associados à matriz de adjacência à esquerda. Crédito:Mitchell &Petzold
p Brian Mitchell e Linda Petzold, dois pesquisadores da Universidade da Califórnia, aplicaram recentemente o aprendizado de reforço profundo sem modelo a modelos de dinâmica neural, alcançando resultados muito promissores. p Aprendizagem por reforço é uma área de aprendizagem de máquina inspirada pela psicologia behaviorista que treina algoritmos para completar tarefas particulares com eficácia, usando um sistema baseado em recompensa e punição. Um marco importante nesta área foi o desenvolvimento da Deep-Q-Network (DQN), que foi inicialmente usado para treinar um computador para jogar jogos Atari.
p A aprendizagem por reforço sem modelo foi aplicada a uma variedade de problemas, mas DQN geralmente não é usado. A principal razão para isso é que o DQN pode propor um número limitado de ações, enquanto os problemas físicos geralmente requerem um método que pode propor um continuum de ações.
p Ao ler a literatura existente sobre controle neural, Mitchell e Petzold notaram o uso difundido de um paradigma clássico para resolver problemas de controle neural com estratégias de aprendizado de máquina. Primeiro, o engenheiro e o experimentador concordam com o objetivo e o desenho de seu estudo. Então, o último executa o experimento e coleta dados, que posteriormente será analisado pelo engenheiro e utilizado para construir um modelo do sistema de interesse. Finalmente, o engenheiro desenvolve um controlador para o modelo e o dispositivo implementa esse controlador.
p
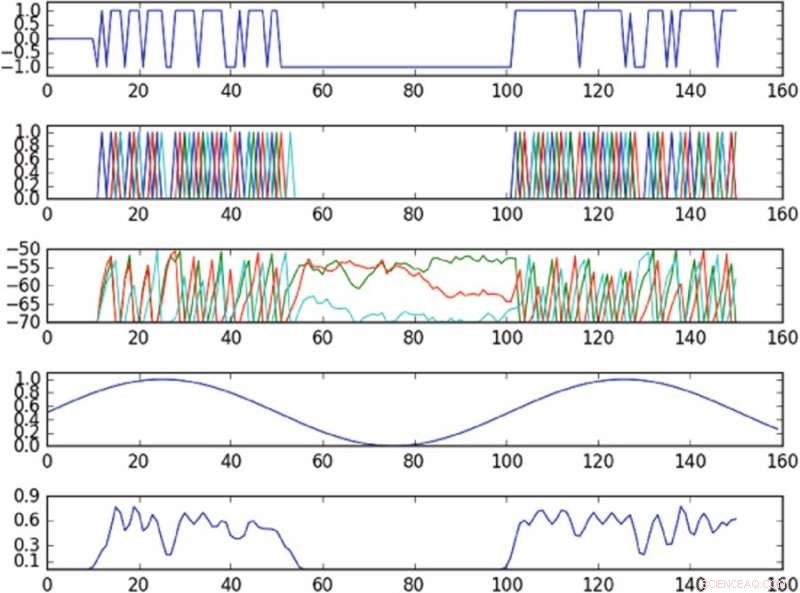 p Resultados do experimento controlando a oscilação no espaço de fase definido por um único componente principal. O primeiro gráfico a partir do topo é um gráfico da entrada na célula acionada ao longo do tempo; o segundo gráfico a partir do topo é um gráfico dos picos de toda a rede, onde cores diferentes correspondem a células diferentes; o terceiro gráfico a partir do topo corresponde ao potencial de membrana de cada célula ao longo do tempo; o quarto gráfico do topo mostra a oscilação alvo; o gráfico inferior mostra a oscilação observada. A política, apesar de fornecer dados para apenas uma única célula, é capaz de induzir aproximadamente a oscilação alvo no espaço de fase observado. Crédito:Mitchell &Petzold
p Resultados do experimento controlando a oscilação no espaço de fase definido por um único componente principal. O primeiro gráfico a partir do topo é um gráfico da entrada na célula acionada ao longo do tempo; o segundo gráfico a partir do topo é um gráfico dos picos de toda a rede, onde cores diferentes correspondem a células diferentes; o terceiro gráfico a partir do topo corresponde ao potencial de membrana de cada célula ao longo do tempo; o quarto gráfico do topo mostra a oscilação alvo; o gráfico inferior mostra a oscilação observada. A política, apesar de fornecer dados para apenas uma única célula, é capaz de induzir aproximadamente a oscilação alvo no espaço de fase observado. Crédito:Mitchell &Petzold
"Este fluxo de trabalho ignora os avanços recentes no controle sem modelo (por exemplo, AlphaGo AlphaGo Zero), o que poderia tornar o projeto de controladores mais eficiente, "Mitchell disse
Tech Xplore . "Em uma estrutura livre de modelos, etapas b, c, ed são combinados em uma única etapa e nenhum modelo explícito é criado. Em vez, o sistema sem modelo interage repetidamente com o sistema neural e aprende com o tempo para atingir o objetivo desejado. Queríamos preencher essa lacuna para ver se o controle sem modelo poderia ser usado para resolver rapidamente novos problemas de controle neural. "
p Os pesquisadores adaptaram um método de aprendizagem por reforço sem modelo denominado "gradientes de política determinística profunda" (DDPG) e aplicaram-no a modelos de dinâmica neural de baixo e alto nível. Eles escolheram especificamente o DDPG porque oferece uma estrutura muito flexível, que não exige que o usuário modele a dinâmica do sistema.
p Uma pesquisa recente descobriu que os métodos sem modelo geralmente precisam de muita experimentação com o ambiente, tornando mais difícil aplicá-los a problemas mais práticos. Apesar disso, os pesquisadores descobriram que sua abordagem livre de modelo teve um desempenho melhor do que os métodos baseados em modelos atuais e foi capaz de resolver problemas de dinâmica neural mais difíceis, como o controle de trajetórias por meio de um espaço de fase latente de uma rede sub-atuada de neurônios.
p "Para os problemas que consideramos neste artigo, abordagens sem modelo eram bastante eficientes e não exigiam muita experimentação, sugerindo que para problemas neurais, controladores de última geração são mais úteis na prática do que as pessoas poderiam imaginar, "disse Mitchell.
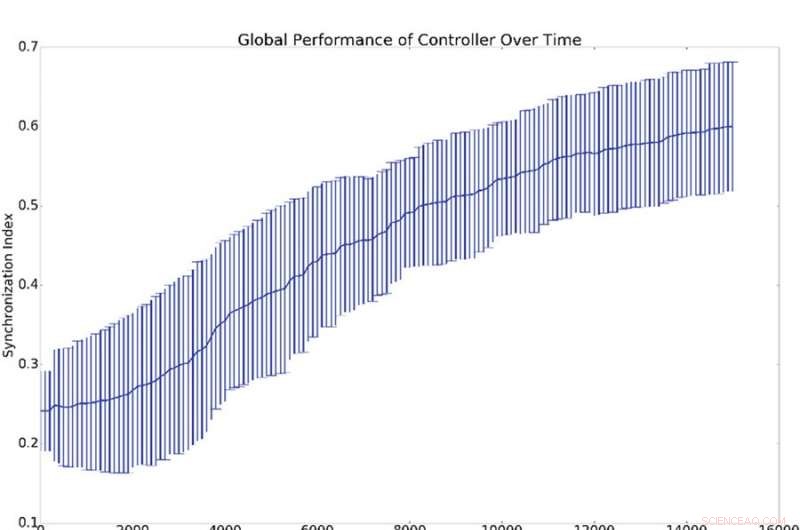 p Resultados resumidos de 10 experimentos de sincronização. (a) Representa a média e o desvio padrão da sincronização global, (ou seja, q da equação 16), contra o número de períodos de treinamento do controlador. (b) Mostra histogramas que demonstram o nível de sincronização de todos os osciladores da rede com o oscilador de referência (ou seja, qi da equação 16). Isso é, um ponto nas curvas azul ou verde demonstra a probabilidade de ter um determinado valor para qi. O histograma azul mostra as contagens antes do treinamento, enquanto o histograma verde mostra as contagens após o treinamento. A sincronização média com a referência, qi, é muito maior do que a sincronização global, q, o que é explicado pelo fato de que a sincronização com a referência é mais fácil de induzir do que a sincronização global. Crédito:Mitchell &Petzold
p Resultados resumidos de 10 experimentos de sincronização. (a) Representa a média e o desvio padrão da sincronização global, (ou seja, q da equação 16), contra o número de períodos de treinamento do controlador. (b) Mostra histogramas que demonstram o nível de sincronização de todos os osciladores da rede com o oscilador de referência (ou seja, qi da equação 16). Isso é, um ponto nas curvas azul ou verde demonstra a probabilidade de ter um determinado valor para qi. O histograma azul mostra as contagens antes do treinamento, enquanto o histograma verde mostra as contagens após o treinamento. A sincronização média com a referência, qi, é muito maior do que a sincronização global, q, o que é explicado pelo fato de que a sincronização com a referência é mais fácil de induzir do que a sincronização global. Crédito:Mitchell &Petzold
p Mitchell e Petzold realizaram seu estudo como uma simulação, portanto, importantes aspectos práticos e de segurança precisam ser considerados antes que seu método possa ser introduzido em ambientes clínicos. Outras pesquisas que incorporam modelos em abordagens livres de modelos, ou que impõe limites aos controladores sem modelo, pode ajudar a aumentar a segurança antes que esses métodos entrem em ambientes clínicos.
p No futuro, os pesquisadores também planejam investigar como os sistemas neurais se adaptam ao controle. Os cérebros humanos são órgãos altamente dinâmicos que se adaptam ao ambiente e mudam em resposta a estímulos externos. Isso pode causar uma competição entre o cérebro e o controlador, particularmente quando seus objetivos não estão alinhados.
p "Em muitos casos, queremos que o controlador vença e o design dos controladores que sempre ganham é um problema importante e interessante, "disse Mitchell." Por exemplo, no caso em que o tecido que está sendo controlado é uma região doente do cérebro, esta região pode ter uma certa progressão que o controlador está tentando corrigir. Em muitas doenças, esta progressão pode resistir ao tratamento (por exemplo, um tumor que se adapta para expulsar a quimioterapia é um exemplo canônico), mas as abordagens livres de modelos atuais não se adaptam bem a esses tipos de mudanças. Melhorar os controladores sem modelos para lidar melhor com a adaptação por parte do cérebro é uma direção interessante que estamos examinando. "
p A pesquisa é publicada em
Relatórios Científicos . p © 2018 Tech Xplore