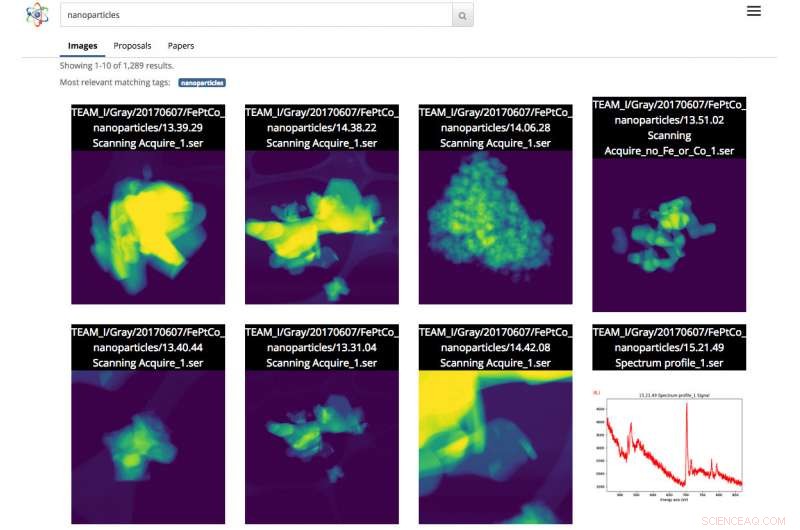
 p Captura de tela da interface do Science Search. Nesse caso, o usuário fez uma pesquisa de imagens de nanopartículas. Crédito:Gonzalo Rodrigo, Berkeley Lab
p Captura de tela da interface do Science Search. Nesse caso, o usuário fez uma pesquisa de imagens de nanopartículas. Crédito:Gonzalo Rodrigo, Berkeley Lab
p Conforme os conjuntos de dados científicos aumentam em tamanho e complexidade, a capacidade de rotular, filtrar e pesquisar este dilúvio de informações tornou-se uma tarefa árdua, tarefa demorada e às vezes impossível, sem a ajuda de ferramentas automatizadas. p Com isso em mente, uma equipe de pesquisadores do Lawrence Berkeley National Laboratory (Berkeley Lab) e da UC Berkeley está desenvolvendo ferramentas inovadoras de aprendizado de máquina para extrair informações contextuais de conjuntos de dados científicos e gerar automaticamente tags de metadados para cada arquivo. Os cientistas podem, então, pesquisar esses arquivos por meio de um mecanismo de pesquisa baseado na web para obter dados científicos, chamado Science Search, que a equipe de Berkeley está construindo.
p Como prova de conceito, a equipe está trabalhando com funcionários da Fundição Molecular do Departamento de Energia (DOE), localizado em Berkeley Lab, demonstrar os conceitos do Science Search nas imagens captadas pelos instrumentos da instalação. Uma versão beta da plataforma foi disponibilizada aos pesquisadores da Foundry.
p "Uma ferramenta como o Science Search tem o potencial de revolucionar nossa pesquisa, "diz Colin Ophus, um cientista pesquisador da Molecular Foundry do National Center for Electron Microscopy (NCEM) e Science Search Collaborator. "Somos uma Central de Usuários Nacional financiada pelo contribuinte, e gostaríamos de tornar todos os dados amplamente disponíveis, em vez do pequeno número de imagens escolhidas para publicação. Contudo, hoje, a maioria dos dados coletados aqui são realmente analisados por um punhado de pessoas - os produtores de dados, incluindo o PI (investigador principal), seus pós-doutorandos ou alunos de pós-graduação - porque atualmente não há uma maneira fácil de filtrar e compartilhar os dados. Ao tornar esses dados brutos facilmente pesquisáveis e compartilháveis, através da internet, A Pesquisa Científica poderia abrir esse reservatório de 'dados obscuros' para todos os cientistas e maximizar o impacto científico de nossas instalações. "
p
Os desafios da pesquisa de dados científicos
p Hoje, motores de busca são usados de forma onipresente para encontrar informações na Internet, mas pesquisar dados científicos apresenta um conjunto diferente de desafios. Por exemplo, O algoritmo do Google se baseia em mais de 200 pistas para realizar uma busca eficaz. Essas pistas podem vir na forma de palavras-chave em uma página da web, metadados em imagens ou feedback do público de bilhões de pessoas quando clicam nas informações que procuram. Em contraste, os dados científicos vêm em muitas formas que são radicalmente diferentes de uma página da web média, requer contexto que é específico para a ciência e muitas vezes também carece de metadados para fornecer o contexto necessário para pesquisas eficazes.
p Nas instalações do usuário nacional, como a Molecular Foundry, pesquisadores de todo o mundo se inscrevem e depois viajam para Berkeley para usar gratuitamente instrumentos extremamente especializados. Ophus observa que as câmeras atuais em microscópios da Foundry podem coletar até um terabyte de dados em menos de 10 minutos. Os usuários precisam filtrar manualmente esses dados para encontrar imagens de qualidade com "boa resolução" e salvar essas informações em um sistema de arquivos compartilhado seguro, como o Dropbox, ou em um disco rígido externo que eventualmente levam para casa para análise.
p Muitas vezes, os pesquisadores que vêm à Molecular Foundry têm apenas alguns dias para coletar seus dados. Porque é muito tedioso e demorado adicionar manualmente notas a terabytes de dados científicos e não há um padrão para fazer isso, a maioria dos pesquisadores apenas digita descrições abreviadas no nome do arquivo. Isso pode fazer sentido para a pessoa que salva o arquivo, mas muitas vezes não faz muito sentido para ninguém.
p "A falta de rótulos de metadados reais eventualmente causa problemas quando o cientista tenta encontrar os dados mais tarde ou tenta compartilhá-los com outras pessoas, "diz Lavanya Ramakrishnan, um cientista da equipe do Berkeley Lab's Computational Research Division (CRD) e co-investigador principal do projeto Science Search. "Mas com técnicas de aprendizado de máquina, podemos ter computadores para ajudar com o que é trabalhoso para os usuários, incluindo a adição de tags aos dados. Então, podemos usar essas tags para pesquisar os dados de forma eficaz. "
p Para resolver o problema dos metadados, a equipe do Berkeley Lab usa técnicas de aprendizado de máquina para explorar o "ecossistema da ciência", incluindo carimbos de data / hora de instrumentos, registros do usuário da instalação, propostas científicas, publicações e estruturas de sistema de arquivos - para informações contextuais. As informações coletivas dessas fontes, incluindo carimbo de data / hora do experimento, notas sobre a resolução e o filtro usados e a solicitação de tempo do usuário, todos fornecem informações contextuais críticas. A equipe do laboratório de Berkeley montou uma pilha de software inovadora que usa técnicas de aprendizado de máquina, incluindo processamento de linguagem natural, puxa palavras-chave contextuais sobre o experimento científico e cria automaticamente tags de metadados para os dados.
p Para a prova de conceito, Ophus compartilhou dados do microscópio eletrônico TEAM 1 da Molecular Foundry no NCEM que foram recentemente coletados pela equipe da instalação, com a equipe de pesquisa científica. Ele também se ofereceu para rotular alguns milhares de imagens para dar às ferramentas de aprendizado de máquina alguns rótulos para começar a aprender. Embora seja um bom começo, O co-investigador principal da Science Search, Gunther Weber, observa que a maioria dos aplicativos de aprendizado de máquina bem-sucedidos geralmente requerem muito mais dados e feedback para fornecer melhores resultados. Por exemplo, no caso de mecanismos de pesquisa como o Google, Weber observa que conjuntos de dados de treinamento são criados e técnicas de aprendizado de máquina são validadas quando bilhões de pessoas ao redor do mundo verificam sua identidade clicando em todas as imagens com placas de rua ou vitrines após digitar suas senhas, ou no Facebook quando estão marcando seus amigos em uma imagem.
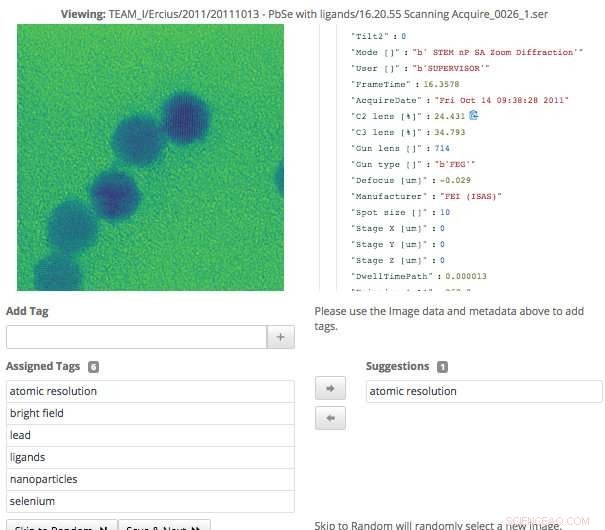 p Esta captura de tela da interface do Science Search mostra como os usuários podem validar facilmente as tags de metadados que foram geradas por meio de aprendizado de máquina, ou adicione informações que ainda não foram capturadas. Crédito:Gonzalo Rodrigo, Berkeley Lab
p Esta captura de tela da interface do Science Search mostra como os usuários podem validar facilmente as tags de metadados que foram geradas por meio de aprendizado de máquina, ou adicione informações que ainda não foram capturadas. Crédito:Gonzalo Rodrigo, Berkeley Lab
p "No caso de dados científicos, apenas alguns especialistas no domínio podem criar conjuntos de treinamento e validar técnicas de aprendizado de máquina, então, um dos grandes problemas contínuos que enfrentamos é um número extremamente pequeno de conjuntos de treinamento, "diz Weber, que também é cientista da equipe do CRD do Berkeley Lab.
p Para superar este desafio, os pesquisadores do Berkeley Lab usaram a aprendizagem por transferência para limitar os graus de liberdade, ou contagens de parâmetros, em suas redes neurais convolucionais (CNNs). O aprendizado por transferência é um método de aprendizado de máquina em que um modelo desenvolvido para uma tarefa é reutilizado como ponto de partida para um modelo em uma segunda tarefa, o que permite ao usuário obter resultados mais precisos de um conjunto de treinamento menor. No caso do microscópio TEAM I, os dados produzidos contêm informações sobre em qual modo de operação o instrumento estava no momento da coleta. Com essa informação, Weber conseguiu treinar a rede neural nessa classificação para que pudesse gerar esse rótulo de modo de operação automaticamente. Ele então congelou a camada convolucional da rede, o que significava que ele só teria que treinar novamente as camadas densamente conectadas. Essa abordagem reduz efetivamente o número de parâmetros na CNN, permitindo que a equipe obtenha alguns resultados significativos de seus dados de treinamento limitados.
p
Aprendizado de máquina para extrair o ecossistema científico
p Além de gerar tags de metadados por meio de conjuntos de dados de treinamento, a equipe do Berkeley Lab também desenvolveu ferramentas que usam técnicas de aprendizado de máquina para minerar o ecossistema científico para o contexto de dados. Por exemplo, o módulo de ingestão de dados pode olhar para uma infinidade de fontes de informação do ecossistema científico, incluindo carimbos de data / hora de instrumentos, registros do usuário, propostas e publicações - e identificar pontos em comum. As ferramentas desenvolvidas no Berkeley Lab que usam métodos de processamento de linguagem natural podem então identificar e classificar palavras que dão contexto aos dados e facilitam resultados significativos para os usuários mais tarde. O usuário verá algo semelhante à página de resultados de uma pesquisa na Internet, onde o conteúdo com a maior parte do texto correspondendo às palavras de pesquisa do usuário aparecerá na parte superior da página. O sistema também aprende com as consultas do usuário e os resultados da pesquisa em que clicam.
p Como os instrumentos científicos estão gerando um corpo cada vez maior de dados, todos os aspectos do mecanismo de pesquisa científica da equipe de Berkeley precisavam ser escalonáveis para acompanhar o ritmo e a escala dos volumes de dados produzidos. A equipe conseguiu isso configurando seu sistema em uma instância Spin no supercomputador Cori no National Energy Research Scientific Computing Center (NERSC). Spin é uma tecnologia de serviços de ponta baseada em Docker desenvolvida na NERSC que pode acessar os sistemas de computação de alto desempenho da instalação e armazenamento no back-end.
p "Uma das razões pelas quais é possível construirmos uma ferramenta como o Science Search é nosso acesso aos recursos do NERSC, "diz Gonzalo Rodrigo, um pesquisador de pós-doutorado do Berkeley Lab que está trabalhando no processamento de linguagem natural e nos desafios de infraestrutura no Science Search. "Temos que armazenar, analisar e recuperar conjuntos de dados realmente grandes, e é útil ter acesso a uma instalação de supercomputação para fazer o trabalho pesado para essas tarefas. O Spin da NERSC é uma ótima plataforma para executar nosso mecanismo de pesquisa, que é um aplicativo voltado para o usuário que requer acesso a grandes conjuntos de dados e dados analíticos que só podem ser armazenados em grandes sistemas de armazenamento de supercomputação. "
p
Uma interface para validar e pesquisar dados
p Quando a equipe do Berkeley Lab desenvolveu a interface para os usuários interagirem com seu sistema, eles sabiam que teria que cumprir alguns objetivos, incluindo pesquisa eficaz e permitindo a entrada humana para os modelos de aprendizado de máquina. Como o sistema depende de especialistas no domínio para ajudar a gerar os dados de treinamento e validar a saída do modelo de aprendizado de máquina, a interface necessária para facilitar isso.
p "A interface de marcação que desenvolvemos exibe os dados e metadados originais disponíveis, bem como quaisquer tags geradas por máquina que temos até agora. Os usuários experientes podem então navegar pelos dados e criar novas tags e revisar quaisquer tags geradas por máquina para precisão, "diz Matt Henderson, que é engenheiro de sistemas de computador em CRD e lidera o esforço de desenvolvimento da interface do usuário.
p Para facilitar uma busca eficaz por usuários com base nas informações disponíveis, a interface de pesquisa da equipe fornece um mecanismo de consulta para os arquivos disponíveis, propostas e documentos que as ferramentas de aprendizado de máquina desenvolvidas por Berkeley analisaram e extraíram tags. Cada item de resultado de pesquisa listado representa um resumo desses dados, com uma visão secundária mais detalhada disponível, incluindo informações sobre tags que correspondem a este item. A equipe está explorando a melhor forma de incorporar o feedback do usuário para melhorar os modelos e tags.
p "Ter a capacidade de explorar conjuntos de dados é importante para descobertas científicas, e esta é a primeira vez que algo como a Pesquisa Científica foi tentada, "diz Ramakrishnan." Nossa visão final é construir a base que irá eventualmente apoiar um 'Google' para dados científicos, onde os pesquisadores podem até pesquisar conjuntos de dados distribuídos. Nosso trabalho atual fornece a base necessária para chegar a essa visão ambiciosa. "
p "O Berkeley Lab é realmente um lugar ideal para construir uma ferramenta como o Science Search, porque temos várias facilidades para o usuário, como a Fundição Molecular, que têm décadas de dados que forneceriam ainda mais valor para a comunidade científica se os dados pudessem ser pesquisados e compartilhados, "adiciona Katie Antypas, que é o principal investigador do Science Search e chefe do Departamento de Dados do NERSC. "Além disso, temos excelente acesso à experiência em aprendizado de máquina na área de Ciências da Computação do Berkeley Lab, bem como a recursos de HPC no NERSC para desenvolver esses recursos."