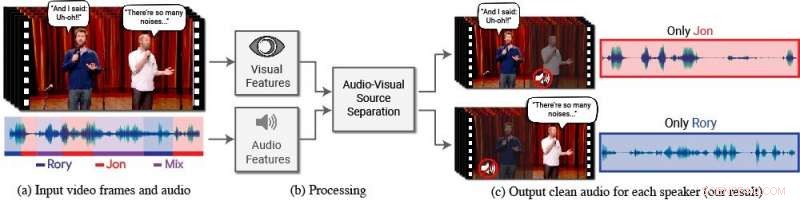
Um novo modelo isola e aprimora a fala dos palestrantes desejados em um vídeo. (a) A entrada é um vídeo (frames + trilha de áudio) com uma ou mais pessoas falando, onde a fala de interesse é interferida por outros alto-falantes e / ou ruído de fundo. (b) Ambos os recursos de áudio e visual são extraídos e alimentados em um modelo de separação de voz audiovisual conjunto. (c) A saída é uma decomposição da trilha de áudio de entrada em trilhas de fala limpas, um para cada pessoa detectada no vídeo. A fala de pessoas específicas é realçada nos vídeos, enquanto todos os outros sons são suprimidos. O novo modelo foi treinado usando milhares de horas de segmentos de vídeo do novo conjunto de dados da equipe, AVSpeech, que será lançado publicamente. Crédito:Autores / Fotos do Google Video:Cortesia da Equipe Coco / CONAN
As pessoas têm um dom natural para se concentrar no que uma única pessoa está dizendo, mesmo quando há conversas concorrentes ao fundo ou outros sons que distraem. Por exemplo, as pessoas muitas vezes conseguem entender o que está sendo dito por alguém em um restaurante lotado, durante uma festa barulhenta, ou enquanto assiste a debates na televisão onde vários especialistas estão falando uns sobre os outros. A data, ser capaz de imitar computacionalmente - e com precisão - essa habilidade humana natural de isolar a fala tem sido uma tarefa difícil.
"Os computadores estão se tornando cada vez melhores na compreensão da fala, mas ainda tem dificuldade significativa em entender a fala quando várias pessoas estão falando juntas ou quando há muito barulho, "diz Ariel Ephrat, um Ph.D. candidato na Universidade Hebraica de Jerusalém-Israel e principal autor da pesquisa. (Ephrat desenvolveu o novo modelo enquanto estagiava no Google no verão de 2017.) "Nós, humanos, sabemos como entender a fala em tais condições naturalmente, mas queremos que os computadores sejam capazes de fazer isso tão bem quanto nós, talvez até melhor. "
Para este fim, Ephrat e seus colegas do Google desenvolveram um novo modelo audiovisual para isolar e aprimorar a fala dos palestrantes desejados em um vídeo. O modelo baseado em rede profunda da equipe incorpora sinais visuais e auditivos para isolar e aprimorar qualquer alto-falante em qualquer vídeo, mesmo em cenários desafiadores do mundo real, como videoconferência, onde vários participantes muitas vezes falam ao mesmo tempo, e bares barulhentos, que pode conter uma variedade de ruídos de fundo, música, e conversas concorrentes.
O time, que inclui o Inbar Mosseri do Google, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, e Michael Rubinstein, apresentará seu trabalho no SIGGRAPH 2018, realizada de 12 a 16 de agosto em Vancouver, Columbia Britânica. A conferência e exposição anual apresenta os principais profissionais do mundo, acadêmicos, e mentes criativas na vanguarda da computação gráfica e técnicas interativas.
Nesse trabalho, os pesquisadores não se concentraram apenas em pistas auditivas para separar a fala, mas também em pistas visuais no vídeo, ou seja, os movimentos dos lábios do sujeito e, potencialmente, outros movimentos faciais que podem contribuir para o que ele ou ela está dizendo. Os recursos visuais obtidos são usados para "focar" o áudio em um único sujeito que está falando e para melhorar a qualidade da separação da fala.
Para treinar seu modelo audiovisual conjunto, Ephrat e colaboradores fizeram a curadoria de um novo conjunto de dados, "AVSpeech, "composta por milhares de vídeos do YouTube e outros segmentos de vídeo online, como TED Talks, vídeos de instruções, e palestras de alta qualidade. Da AVSpeech, os pesquisadores geraram um conjunto de treinamento dos chamados "coquetéis sintéticos" - misturas de vídeos de rosto com fala limpa e outras trilhas de áudio de fala com ruído de fundo. Para isolar a fala desses vídeos, o usuário só precisa especificar o rosto da pessoa no vídeo cujo áudio deve ser destacado.
Em vários exemplos detalhados no artigo, intitulado "Olhando para ouvir no coquetel:um modelo audiovisual independente de alto-falante para separação de fala, "o novo método apresentou resultados superiores em comparação aos métodos existentes apenas de áudio em misturas de voz pura, e melhorias significativas na entrega de áudio claro de misturas contendo fala sobreposta e ruído de fundo em cenários do mundo real. Embora o foco do trabalho seja a separação e o aprimoramento da fala, o novo método da equipe também pode ser aplicado ao reconhecimento automático de fala (ASR) e transcrição de vídeo, ou seja, recursos de legenda oculta em streaming de vídeos e TV. Em uma demonstração, o novo modelo audiovisual conjunto produziu legendas mais precisas em cenários onde dois ou mais alto-falantes estavam envolvidos.
Surpreso no início com o quão bem seu método funcionava, os pesquisadores estão entusiasmados com seu potencial futuro.
"Não vimos a separação de fala feita 'in-the-wild' com tal qualidade antes. É por isso que vemos um futuro empolgante para esta tecnologia, "observa Ephrat." Há mais trabalho necessário antes que essa tecnologia chegue às mãos do consumidor, mas com os resultados preliminares promissores que mostramos, certamente podemos vê-lo suportando uma variedade de aplicativos no futuro, como legendas de vídeo, vídeo conferência, e até aparelhos auditivos aprimorados se tais dispositivos pudessem ser combinados com câmeras. "
Os pesquisadores estão explorando oportunidades para incorporá-lo em vários produtos do Google.