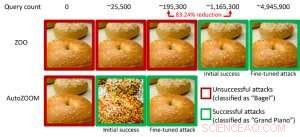
Figura 1:Comparação de desempenho ao transformar uma imagem de bagel em uma imagem de bagel adversária classificada como um “piano de cauda” usando ataques ZOO e AutoZOOM. Crédito:IBM
Estudos recentes identificaram a falta de robustez nos modelos de IA atuais contra exemplos adversários - entradas de dados evasivas de predição manipuladas intencionalmente que são semelhantes aos dados normais, mas farão com que modelos de IA bem treinados se comportem mal. Por exemplo, perturbações visualmente imperceptíveis em um sinal de parada podem ser facilmente criadas e levar um modelo de IA de alta precisão a uma classificação incorreta. Em nosso artigo anterior publicado na European Conference on Computer Vision (ECCV) em 2018, validamos que 18 diferentes modelos de classificação treinados na ImageNet, um grande conjunto de dados de reconhecimento de objeto público, são todos vulneráveis a perturbações adversárias.
Notavelmente, exemplos adversários são frequentemente gerados na configuração de "caixa branca", onde o modelo de IA é totalmente transparente para um adversário. No cenário prático, ao implantar um modelo de IA autodidata como serviço, como uma API de classificação de imagem online, pode-se acreditar erroneamente que é robusto para exemplos adversários devido ao acesso e conhecimento limitados sobre o modelo de IA subjacente (também conhecido como configuração de "caixa preta"). Contudo, nosso trabalho recente publicado na AAAI 2019 mostra que a robustez devido ao acesso limitado do modelo não é aterrada. Fornecemos uma estrutura geral para gerar exemplos adversários do modelo de IA de destino usando apenas as respostas de entrada-saída do modelo e poucas consultas de modelo. Em comparação com o trabalho anterior (ataque ZOO), nossa estrutura proposta, chamado AutoZOOM, reduz pelo menos 93% de consultas de modelo em média, enquanto atinge desempenho de ataque semelhante, fornecendo uma metodologia de consulta eficiente para avaliar a robustez adversária de sistemas de IA com acesso limitado. Um exemplo ilustrativo é mostrado na Figura 1, onde uma imagem de bagel adversária gerada a partir de um classificador de imagem de caixa preta será classificada como o alvo de ataque "piano de cauda". Este artigo foi selecionado para apresentação oral (29 de janeiro de 11h30-12h30 @ coral 1) e apresentação do pôster (29 de janeiro, 18h30 - 20h30) no AAAI 2019.
Na configuração da caixa branca, exemplos adversários são muitas vezes criados aproveitando o gradiente de um objetivo de ataque projetado em relação à entrada de dados para a orientação da perturbação adversária, que requer conhecer a arquitetura do modelo, bem como os pesos do modelo para inferência. Contudo, na configuração da caixa preta, adquirir o gradiente é inviável devido ao acesso limitado a esses detalhes do modelo. Em vez de, um adversário só pode acessar as respostas de entrada-saída do modelo de IA implantado, assim como usuários regulares (por exemplo, carregue uma imagem e receba a previsão de uma API de classificação de imagem online). Foi mostrado pela primeira vez no ataque ZOO que a geração de exemplos adversários a partir de modelos com acesso limitado é possível usando técnicas de estimativa de gradiente. Contudo, pode ser necessária uma grande quantidade de consultas de modelo para criar um exemplo adversário. Por exemplo, na Figura 1, O ataque ZOO leva mais de 1 milhão de consultas de modelos para encontrar a imagem do bagel adversário. Para acelerar a eficiência da consulta na localização de exemplos adversários na configuração da caixa preta, nosso framework AutoZOOM proposto tem dois novos blocos de construção:(i) uma estratégia de estimativa de gradiente aleatório adaptável para equilibrar contagens de consulta e distorção, e (ii) um autoencoder que é treinado offline com dados não rotulados ou uma operação de redimensionamento bilinear para aceleração. Para (i), AutoZOOM apresenta um estimador de gradiente otimizado e eficiente em consultas, que tem um esquema adaptativo que usa poucas consultas para encontrar a primeira perturbação adversária bem-sucedida e, em seguida, usa mais consultas para ajustar a distorção e tornar o exemplo adversário mais realista. Para (ii), como mostrado na Figura 2, AutoZOOM implementa uma técnica chamada "redução de dimensão" para reduzir a complexidade de encontrar exemplos adversários. A redução de dimensão pode ser realizada por um autencoder treinado offline para capturar características de dados ou um redimensionador de imagem bilinear simples que não requer nenhum treinamento.
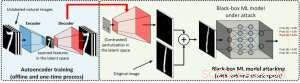
Figura 2:Ilustração da técnica de redução de dimensão usada no AutoZOOM para resgates de consultas. O decodificador pode ser um autencoder treinado offline ou uma operação de redimensionamento bilinear que não requer nenhum treinamento. Crédito:IBM
Com essas duas técnicas básicas, nossos experimentos em classificadores de imagem baseados em rede neural profunda de caixa preta treinados em MNIST, O CIFAR-10 e o ImageNet mostram que o AutoZOOM atinge um desempenho de ataque semelhante, ao mesmo tempo que atinge uma redução significativa (pelo menos 93%) nas contagens médias de consulta em comparação com o ataque ZOO. Na ImageNet, essa redução drástica significa milhões de consultas de modelo a menos, tornando AutoZOOM uma ferramenta eficiente e prática para avaliar a robustez adversária de modelos de IA com acesso limitado. Além disso, AutoZOOM é um acelerador de resgate de consulta geral que pode ser aplicado prontamente a diferentes métodos para gerar exemplos adversários na configuração prática da caixa preta.
O código AutoZOOM é open-source e pode ser encontrado aqui. Consulte também Adversarial Robustness Toolbox da IBM para obter mais implementações em ataques e defesas adversárias.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.