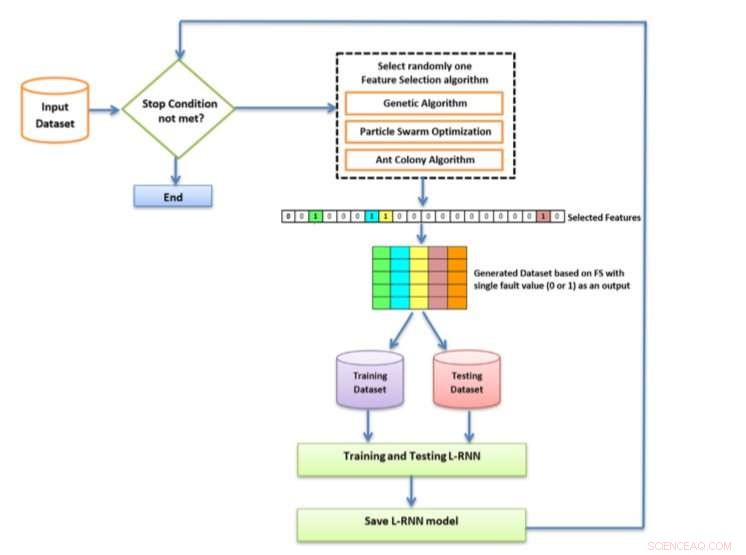
Um diagrama pictórico da metodologia proposta. Crédito:Turabieh, Mafarja &Li.
Pesquisadores da Universidade Taif, Birzeit University e RMIT University desenvolveram uma nova abordagem para previsão de falha de software (SFP), que aborda algumas das limitações das técnicas SFP de aprendizado de máquina existentes. Sua abordagem emprega seleção de recursos (FS) para melhorar o desempenho de uma rede neural recorrente em camadas (L-RNN), que é usado como uma ferramenta de classificação para SFP.
A previsão de falha de software (SFP) é o processo de prever módulos que são propensos a falhas em software recém-desenvolvido. Prever falhas em componentes de software antes de serem entregues ao usuário final é de fundamental importância, pois pode economizar tempo, esforço e inconveniência associados à identificação e abordagem dessas questões em um estágio posterior.
Nos últimos anos, técnicas de aprendizado de máquina, como redes neurais, regressão logística, máquinas de vetores de suporte e classificadores de conjunto provaram ser muito eficazes no combate ao SFP. Contudo, devido ao enorme conjunto de dados que podem ser obtidos por mineração de repositórios históricos de software, é possível encontrar características que não estão relacionadas com as falhas. Isso às vezes pode enganar o algoritmo de aprendizagem, conseqüentemente diminuindo seu desempenho.
A seleção de recursos (FS) é uma técnica que pode ajudar a eliminar esses recursos não relacionados sem prejudicar o desempenho do algoritmo de aprendizado de máquina. No aprendizado de máquina, a seleção de recursos envolve a seleção de um subconjunto de recursos relevantes (ou seja, preditores) a serem usados em um modelo específico. FS pode reduzir a dimensionalidade dos dados; removendo dados irrelevantes e redundantes.
Em seu jornal, publicado em Sistemas especialistas com aplicativos , a equipe de pesquisa da Universidade Taif, Birzeit University e RMIT University propuseram uma nova abordagem FS para melhorar o desempenho de uma rede neural recorrente em camadas (L-RNN) para SFP. Os pesquisadores empregaram três algoritmos FS wrapper diferentes de forma iterativa:algoritmo genético binário (BGA), otimização de enxame de partículas binárias (BPSO), e otimização de colônia de formigas binárias (BACO).
"Propusemos um algoritmo de seleção de recursos iterados com uma rede neural recorrente em camadas para resolver o problema de previsão de falhas de software, "os pesquisadores escreveram em seu artigo." O algoritmo proposto é capaz de selecionar as métricas de software mais importantes usando diferentes algoritmos de seleção de recursos. O processo de classificação é realizado por uma rede neural recorrente em camadas. "
Os pesquisadores avaliaram sua abordagem em 19 projetos de software do mundo real do repositório PROMISE e compararam seus resultados com aqueles obtidos usando outras abordagens de última geração, incluindo Naïve Bayes (NB), redes neurais artificiais (ANNs), regressão logística (LR), os k-vizinhos mais próximos (k-NN) e árvores de decisão C4.5. A abordagem deles superou todos os outros métodos existentes, alcançando uma taxa média de classificação de 0,8358 em todos os conjuntos de dados.
"Os resultados obtidos apoiam nossa afirmação da importância da seleção de recursos na construção de um classificador de alta qualidade, em vez de usar um conjunto fixo de recursos ou todos os recursos, "os pesquisadores explicaram em seu artigo." Para trabalhos futuros, pretendemos investigar o desempenho de diferentes classificadores, como a programação genética, para construir um modelo de computador que seja capaz de prever falhas com base em métricas selecionadas. "
© 2019 Science X Network