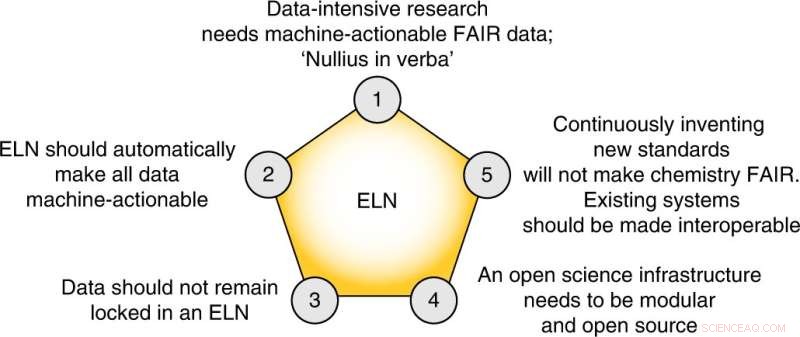
As cinco teses centrais desta perspectiva. Crédito:Natureza Química (2022). DOI:10.1038/s41557-022-00910-7
Um dos aspectos mais desafiadores da química moderna é o gerenciamento de dados. Por exemplo, ao sintetizar um novo composto, os cientistas passarão por várias tentativas de tentativa e erro para encontrar as condições certas para a reação, gerando no processo enormes quantidades de dados brutos. Esses dados têm um valor incrível, pois, como os humanos, os algoritmos de aprendizado de máquina podem aprender muito com experimentos fracassados e parcialmente bem-sucedidos.
A prática atual é, no entanto, publicar apenas os experimentos mais bem-sucedidos, já que nenhum humano pode processar significativamente o grande número de experimentos fracassados. Mas a IA mudou isso; é exatamente o que esses métodos de aprendizado de máquina podem fazer, desde que os dados sejam armazenados em um formato acionável por máquina para qualquer pessoa usar.
"Durante muito tempo, precisávamos comprimir informações devido à contagem limitada de páginas em artigos de periódicos impressos", diz o professor Berend Smit, que dirige o Laboratório de Simulação Molecular da EPFL Valais Wallis. "Hoje em dia, muitos periódicos não têm mais edições impressas; no entanto, os químicos ainda lutam com problemas de reprodutibilidade porque os artigos de periódicos estão perdendo detalhes cruciais. resultados publicados como dados brutos raramente são publicados."
Mas o volume não é o único problema aqui; a diversidade de dados é outra:os grupos de pesquisa utilizam ferramentas diferentes, como o software Electronic Lab Notebook, que armazena dados em formatos proprietários que às vezes são incompatíveis entre si. Essa falta de padronização torna quase impossível para os grupos compartilharem dados.
Agora, Smit, com Luc Patiny e Kevin Jablonka na EPFL, publicou uma perspectiva em
Nature Chemistry apresentando uma plataforma aberta para todo o fluxo de trabalho da química:desde o início de um projeto até sua publicação.
Os cientistas imaginam a plataforma como integrando "perfeitamente" três etapas cruciais:coleta de dados, processamento de dados e publicação de dados - tudo com custo mínimo para os pesquisadores. O princípio orientador é que os dados devem ser JUSTOS:facilmente localizáveis, acessíveis, interoperáveis e reutilizáveis. "No momento da coleta de dados, os dados serão convertidos automaticamente em um formato FAIR padrão, possibilitando a publicação automática de todos os experimentos 'falhados' e parcialmente bem-sucedidos juntamente com o experimento mais bem-sucedido", diz Smit.
Mas os autores vão um passo além, propondo que os dados também devem ser acionáveis por máquina. "Estamos vendo cada vez mais estudos de ciência de dados em química", diz Jablonka. "De fato, resultados recentes em aprendizado de máquina tentam resolver alguns dos problemas que os químicos acreditam serem insolúveis. Por exemplo, nosso grupo fez um enorme progresso na previsão de condições ideais de reação usando modelos de aprendizado de máquina. Mas esses modelos seriam muito mais valiosos se eles também podem aprender condições de reação que falham, mas, caso contrário, elas permanecem tendenciosas porque apenas as condições de sucesso são publicadas."
Finalmente, os autores propõem cinco passos concretos que o campo deve seguir para criar um plano de gerenciamento de dados FAIR:
- A comunidade química deve adotar seus próprios padrões e soluções existentes.
- Os periódicos precisam tornar obrigatória a deposição de dados brutos reutilizáveis, onde existam padrões da comunidade.
- Precisamos adotar a publicação de experimentos "fracassados".
- Cadernos eletrônicos de laboratório que não permitem a exportação de todos os dados em um formulário aberto acionável por máquina devem ser evitados.
- A pesquisa com uso intensivo de dados deve entrar em nossos currículos.
"Achamos que não há necessidade de inventar novos formatos de arquivo ou tecnologias", diz Patiny. "Em princípio, toda a tecnologia está lá, e precisamos abraçar as tecnologias existentes e torná-las interoperáveis."
Os autores também apontam que apenas armazenar dados em qualquer notebook de laboratório eletrônico – a tendência atual – não significa necessariamente que humanos e máquinas possam reutilizar os dados. Em vez disso, os dados devem ser estruturados e publicados em um formato padronizado e também devem conter contexto suficiente para permitir ações orientadas por dados.
“Nossa perspectiva oferece uma visão do que pensamos ser os principais componentes para preencher a lacuna entre dados e aprendizado de máquina para problemas centrais em química”, diz Smit. "Também fornecemos uma solução de ciência aberta na qual a EPFL pode assumir a liderança."
+ Explorar mais O aprendizado de máquina quebra os estados de oxidação das estruturas cristalinas