
Comparação de classificações de conceitos para um Relatório da Human Rights Watch. A coluna 'Verdadeira' mostra as oito pessoas mencionadas com mais frequência no relatório 'Crise Humanitária da Venezuela', enquanto as outras colunas mostram os valores retornados por vários métodos de descoberta. Os valores que estão entre os conceitos de verdade fundamental são indicados por caixas escuras. O método de contexto retorna valores que são todos relevantes (mesmo se ausentes do artigo original), enquanto o método de co-ocorrência retorna muitos conceitos populares, mas irrelevantes (por exemplo, políticos que fazem declarações gerais sobre o assunto). Crédito:IBM
Na IBM Research AI, construímos uma solução baseada em IA para auxiliar os analistas na preparação de relatórios. O artigo que descreve este trabalho ganhou recentemente o prêmio de melhor artigo na trilha "In-Use" da Conferência Estendida da Web Semântica 2018 (ESWC).
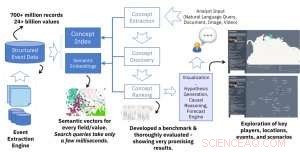
Os analistas são frequentemente encarregados de preparar relatórios abrangentes e precisos sobre determinados tópicos ou questões de alto nível, que pode ser usado por organizações, empreendimentos, ou agências governamentais para tomar decisões informadas, reduzindo o risco associado aos seus planos futuros. Para preparar esses relatórios, os analistas precisam identificar tópicos, pessoas, organizações, e eventos relacionados às perguntas. Como um exemplo, para preparar um relatório sobre as consequências do Brexit nos mercados financeiros de Londres, um analista precisa estar ciente dos principais tópicos relacionados (por exemplo, mercados financeiros, economia, Brexit, Brexit Divorce Bill), pessoas e organizações (por exemplo, A União Europeia, tomadores de decisão na UE e no Reino Unido, pessoas envolvidas nas negociações do Brexit), e eventos (por exemplo, Reuniões de negociação, Eleições parlamentares na UE, etc.). Uma solução assistida por IA pode ajudar os analistas a preparar relatórios completos e também evitar preconceitos com base em experiências anteriores. Por exemplo, um analista pode perder uma fonte importante de informação se ela não tiver sido usada efetivamente no passado.
A equipe de indução de conhecimento da IBM Research AI construiu a solução usando aprendizado profundo e dados de eventos estruturados. O time, liderado por Alfio Gliozzo, também ganhou o prestigioso prêmio Semantic Web Challenge no ano passado.
Embeddings semânticos de bancos de dados de eventos
A principal novidade técnica deste trabalho é a criação de embeddings semânticos a partir de dados de eventos estruturados. A entrada para nosso mecanismo de embeddings semânticos é uma grande fonte de dados estruturados (por exemplo, tabelas de banco de dados com milhões de linhas) e a saída é uma grande coleção de vetores com um tamanho constante (por exemplo, 300) onde cada vetor representa o contexto semântico de um valor nos dados estruturados. A ideia central é semelhante à ideia popular e amplamente usada de incorporação de palavras no processamento de linguagem natural, mas em vez de palavras, representamos valores nos dados estruturados. O resultado é uma solução poderosa que permite uma pesquisa semântica rápida e eficaz em diferentes campos do banco de dados. Uma única consulta de pesquisa leva apenas alguns milissegundos, mas recupera resultados com base na mineração de centenas de milhões de registros e bilhões de valores.
Enquanto experimentávamos vários modelos de rede neural para a construção de embeddings, obtivemos resultados muito promissores usando uma adaptação simples do modelo original skip-gram word2vec. Este é um modelo de rede neural superficial eficiente baseado em uma arquitetura que prevê o contexto (palavras ao redor) dada a uma palavra em um documento. Em nosso trabalho, não estamos lidando com documentos de texto, mas com registros de bancos de dados estruturados. Por esta, não precisamos mais usar uma janela deslizante de tamanho fixo ou aleatório para capturar o contexto. Em dados estruturados, o contexto é definido por todos os valores na mesma linha, independentemente da posição da coluna, já que duas colunas adjacentes em um banco de dados são tão relacionadas quanto quaisquer outras duas colunas. A outra diferença em nossas configurações é a necessidade de capturar diferentes campos (ou colunas) no banco de dados. Nosso mecanismo precisa permitir consultas semânticas gerais (ou seja, retorna qualquer valor de banco de dados relacionado ao valor fornecido) e valores específicos de campo (ou seja, retornar valores de um determinado campo relacionado ao valor de entrada). Por esta, atribuímos um tipo aos vetores construídos a partir de cada campo e construímos um índice que suporta consultas específicas de tipo ou genéricas.
Crédito:IBM
Para o trabalho descrito em nosso artigo, usamos três bancos de dados de eventos disponíveis publicamente como entrada:GDELT, ICEWS, e EventRegistry. Geral, esses bancos de dados consistem em centenas de milhões de registros (objetos JSON ou linhas de banco de dados) e bilhões de valores em vários campos (atributos). Usando nosso mecanismo de embeddings, cada valor se transforma em um vetor que representa o contexto nos dados.
Uma consulta de recuperação simples
Pode-se ver o quão bem o contexto é capturado por nosso mecanismo usando uma consulta de recuperação simples. Por exemplo, ao consultar o valor "Hilary Clinton" (erro ortográfico) no campo "pessoa" no GDELT GKG, o primeiro acerto ou o vetor mais semelhante é "Hilary Clinton" (com grafia incorreta) no campo "nome" e os próximos vetores mais semelhantes são "Hillary Clinton" (grafia correta) nos campos "pessoa" e "nome". Isso se deve ao contexto muito semelhante do valor com grafia incorreta e da grafia correta, e também os valores entre os campos "nome" e "pessoa". O resto dos resultados da consulta acima incluem políticos dos EUA, particularmente aqueles ativos durante as últimas eleições presidenciais, bem como organizações relacionadas, pessoas com funções de trabalho semelhantes no passado, e membros da família.
Pesquisa de similaridade em consultas combinadas
Claro, nossa solução é capaz de alcançar muito mais do que uma simples consulta de recuperação. Em particular, pode-se combinar essas consultas para transformar um conjunto de valores extraídos de uma consulta de linguagem natural em um vetor e realizar a pesquisa por similaridade. Avaliamos o resultado desta abordagem usando uma referência construída a partir de relatórios escritos por especialistas humanos, e examinamos a capacidade de nosso mecanismo de retornar os conceitos descritos nos relatórios usando o título do relatório como a única entrada. Os resultados mostraram claramente a superioridade de nossa abordagem de descoberta de conceito baseada em embeddings semânticos em comparação com uma abordagem de linha de base baseada apenas na coocorrência dos valores.
Novas aplicações na descoberta de conceitos
Um aspecto muito interessante do nosso framework é que qualquer valor e qualquer campo é atribuído a um vetor que representa seu contexto, que permite novas aplicações interessantes. Por exemplo, incorporamos coordenadas de latitude e longitude de eventos nos bancos de dados no mesmo espaço semântico de conceitos, e trabalhou com o Visual AI Lab liderado por Mauro Martino para construir uma estrutura de visualização que destaca locais relacionados em um mapa geográfico a uma pergunta em linguagem natural. Outra aplicação interessante que estamos investigando atualmente é usar os conceitos recuperados e seus embeddings semânticos como recursos para um modelo de aprendizado de máquina que o analista precisa construir. Isso pode ser usado em um mecanismo automatizado de aprendizado de máquina e ciência de dados (AutoML), e analistas de suporte em outro aspecto importante de seus trabalhos. Estamos planejando integrar esta solução no Scenario Planning Advisor da IBM, um sistema de apoio à decisão para analistas de risco.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.














