Centro de dados do CERN. Crédito:Robert Hradil, Monika Majer / ProStudio22.ch
Em 29 de junho de 2017, o CERN DC ultrapassou a marca de 200 petabytes de dados arquivados permanentemente em suas bibliotecas de fitas. De onde vêm esses dados? As partículas colidem nos detectores do Large Hadron Collider (LHC) aproximadamente 1 bilhão de vezes por segundo, gerando cerca de um petabyte de dados de colisão por segundo. Contudo, tais quantidades de dados são impossíveis para os sistemas de computação atuais registrar e, portanto, são filtradas pelos experimentos, mantendo apenas os mais "interessantes". Os dados filtrados do LHC são então agregados no CERN Data Center (DC), onde a reconstrução inicial dos dados é realizada, e onde uma cópia é arquivada em um armazenamento em fita de longo prazo. Mesmo após a redução drástica de dados realizada pelos experimentos, o CERN DC processa em média um petabyte de dados por dia. É assim que a marca de 200 petabytes de dados arquivados permanentemente em suas bibliotecas de fitas foi atingida em 29 de junho.
Os quatro grandes experimentos do LHC produziram volumes de dados sem precedentes nos últimos dois anos. Isso se deve em grande parte ao excelente desempenho e disponibilidade do próprio LHC. De fato, em 2016, as expectativas eram inicialmente de cerca de 5 milhões de segundos de coleta de dados, enquanto o total final foi de cerca de 7,5 milhões de segundos, um aumento muito bem-vindo de 50%. 2017 está seguindo uma tendência semelhante.
Avançar, como a luminosidade é maior do que em 2016, muitas colisões se sobrepõem e os eventos são mais complexos, exigindo reconstrução e análise cada vez mais sofisticadas. Isso tem um forte impacto nos requisitos de computação. Consequentemente, registros estão sendo quebrados em muitos aspectos da aquisição de dados, taxas de dados e volumes de dados, com níveis excepcionais de uso de recursos de computação e armazenamento.
Para enfrentar esses desafios, a infraestrutura de computação em geral, e principalmente os sistemas de armazenamento, passou por grandes atualizações e consolidação durante os dois anos de Long Shutdown 1. Essas atualizações permitiram ao data center lidar com os 73 petabytes de dados recebidos em 2016 (49 dos quais eram dados do LHC) e com o fluxo de dados entregue até agora em 2017. Essas atualizações também permitiram que o sistema CERN Advanced STORage (CASTOR) ultrapassasse o marco desafiador de 200 petabytes de dados arquivados permanentemente. Esses dados arquivados permanentemente representam uma fração importante da quantidade total de dados recebidos no data center do CERN, o resto são dados temporários que são limpos periodicamente.
Outra consequência dos maiores volumes de dados é uma maior demanda por transferência de dados e, portanto, uma necessidade de maior capacidade de rede. Desde o início de fevereiro, um terceiro circuito de fibra óptica de 100 Gb / s (gigabit por segundo) liga o CERN DC à sua extensão remota hospedada no Wigner Research Center for Physics (RCP) na Hungria, 1800km de distância. A largura de banda adicional e a redundância fornecidas por este terceiro link ajudam o CERN a se beneficiar de forma confiável do poder de computação e armazenamento no ramal remoto. Um must-have no contexto de necessidades crescentes de computação!
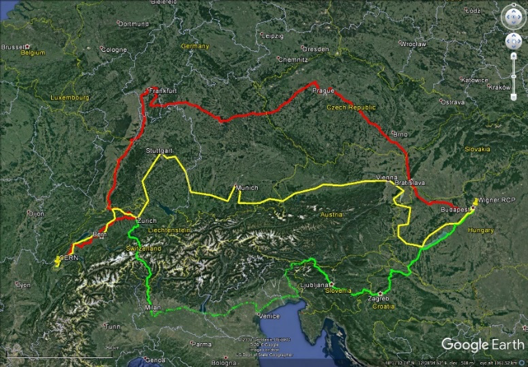
Este mapa mostra as rotas para os três links de fibra de 100 Gbit / s entre o CERN e o Wigner RCP. As rotas foram escolhidas com cuidado para garantir que manteremos a conectividade em caso de qualquer incidente. (Imagem:Google)