O universo das regiões do discurso segregadas pelo FRS. Crédito:Zabihimayvan &Doran.
Nas décadas recentes, ataques de phishing estão se tornando cada vez mais comuns. Esses ataques permitem que os invasores obtenham dados confidenciais do usuário, como senhas, nomes de usuário, detalhes do cartão de crédito, etc, enganando as pessoas para que revelem informações pessoais. O tipo mais comum de ataque de phishing são os golpes de e-mail nos quais os usuários são levados a acreditar que precisam fornecer seus dados a uma entidade estabelecida ou confiável, enquanto eles estão, na verdade, compartilhar esses dados com outra pessoa.
Os profissionais de TI desenvolveram um grande número de ferramentas e estratégias para detectar e prevenir ataques de phishing, muitos dos quais são baseados em aprendizado de máquina. O desempenho de tais algoritmos de aprendizado de máquina geralmente depende dos recursos que extraem dos sites.
Pesquisadores da Wright State University desenvolveram recentemente um novo método para identificar os melhores conjuntos de recursos para algoritmos de detecção de ataques de phishing. A abordagem deles, descrito em um artigo pré-publicado no arXiv, pode ajudar a melhorar o desempenho de algoritmos de aprendizado de máquina individuais para descobrir ataques de phishing.
"O desempenho dos algoritmos de detecção de phishing que usam aprendizado de máquina depende fortemente dos recursos de um site que o algoritmo considera, incluindo o comprimento do URL da página da web ou se caracteres especiais como @ e traço existem no URL, "Mahdieh Zabihimayvan e Derek Doran, os dois pesquisadores que realizaram o estudo, disse TechXplore por e-mail. "Nesse trabalho, queríamos facilitar a construção de algoritmos de aprendizado de máquina para detecção de phishing, recuperando automaticamente um 'melhor' conjunto de recursos para qualquer algoritmo de detecção de phishing, independentemente do site em consideração. "
Embora agora existam vários algoritmos para identificar ataques de phishing, até aqui, muito poucos estudos se concentraram em determinar os recursos mais eficazes para detectar esse tipo específico de ataque. Em seu estudo, Zabihimayvan e Doran abordaram essa lacuna na literatura, tentando descobrir os recursos mais eficazes para essa tarefa específica.
"Aplicamos a teoria Fuzzy Rough Set (FRS) como uma ferramenta para selecionar os recursos mais eficazes de três conjuntos de dados de sites de phishing comparados, "Zabihimayvan e Doran disseram." Os recursos selecionados são então usados por três algoritmos de aprendizado de máquina usados com freqüência para detecção de phishing. "
Para testar a eficácia e generalização de sua abordagem de seleção de recursos FRS, os pesquisadores usaram para treinar três classificadores de detecção de phishing comumente empregados em um conjunto de dados de 14, 000 amostras de sites e, em seguida, avaliaram seu desempenho. Suas avaliações produziram resultados altamente promissores, alcançando uma medida F máxima de 95 por cento quando seu método de seleção de características foi aplicado a um classificador de floresta aleatória (RM).
"O FRS descobre dependências de recursos com base nos dados, "Zabihimayvan e Doran explicaram." Em outras palavras, O FRS decide como separar um conjunto de dados com base em seus valores de característica e rótulos usando um limite de decisão e uma relação de similaridade declarada na forma de funções de pertinência difusas. Os recursos selecionados pelo FRS são os que mais podem distinguir entre as amostras de dados que pertencem a classes diferentes. "
A abordagem FRS usada por Zabihimayvan e Doran selecionou nove recursos universais em todos os conjuntos de dados usados em seu estudo. Usando este conjunto universal de recursos, eles alcançaram uma medida F de aproximadamente 93 por cento, que é semelhante ao obtido por classificadores usando sua abordagem FRS. O conjunto de recursos universais não contém recursos de serviços de terceiros, portanto, essa descoberta sugere que é possível detectar ataques de phishing mais rapidamente, sem consulta de fontes externas.
"Os recursos selecionados automaticamente pelo FRS geram o melhor desempenho de detecção em uma série de classificadores, "Zabihimayvan e Doran disseram." Também encontramos um conjunto de 'recursos universais' - aqueles aspectos de uma página da web que o FRS descobriu para prever melhor se uma página está tentando pescar informações, não importa o tipo de site que a página tente imitar. "
O estudo realizado por Zabihimayvan e Doran é um dos primeiros a fornecer informações valiosas sobre os recursos mais eficazes para detectar ataques de phishing. No futuro, seu trabalho pode abrir caminho para o desenvolvimento de técnicas de detecção de phishing mais eficientes e confiáveis, que descobriria esses ataques mais rápido do que os métodos atuais.
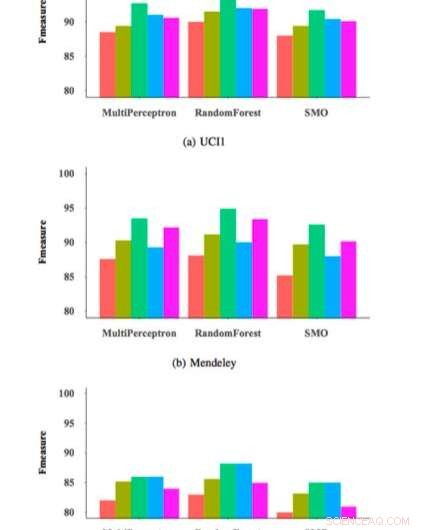
F-measure para diferentes classificadores e conjuntos de recursos. Crédito:Zabihimayvan &Doran.
"Esperamos agora estender nosso estudo ainda mais, investigando a seleção de recursos para algoritmos de aprendizado de máquina mais sofisticados, incluindo arquiteturas de aprendizado profundo que descobrem automaticamente 'meta-recursos' para aprimorar ainda mais o desempenho de detecção, "Zabihimayvan e Doran disseram." Também planejamos estender nossa estrutura de seleção de recursos para detectar e-mails de phishing. "
© 2019 Science X Network














